## Flowchart: Logical Reasoning Process with Premises and Conclusions
### Overview
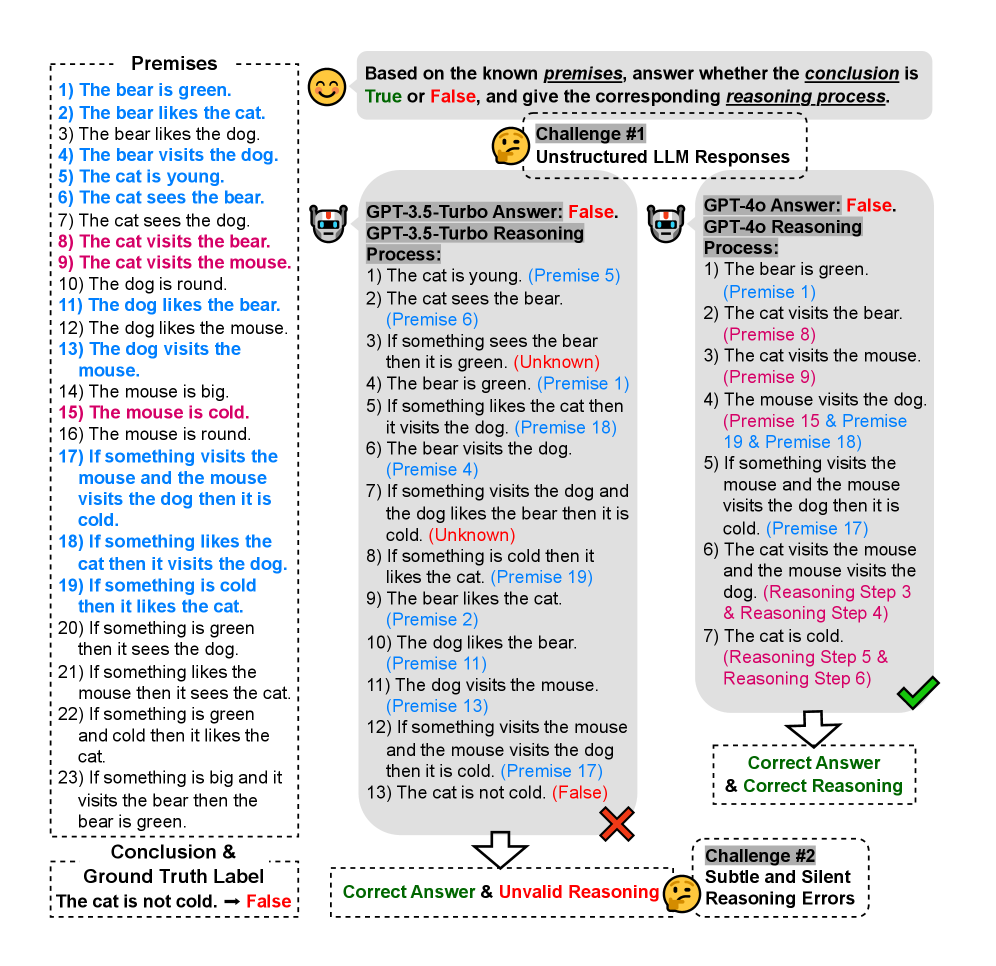
The image depicts a structured logical reasoning task with 23 premises, a conclusion ("The cat is not cold"), and two model-generated reasoning processes (GPT-3.5-Turbo and GPT-4). It highlights challenges in unstructured responses and subtle reasoning errors.
### Components/Axes
1. **Premises**:
- 23 numbered statements (e.g., "The bear is green," "The cat visits the mouse").
- Color-coded:
- **Blue**: Conditional premises (e.g., "If something is green...").
- **Red**: Negative premises (e.g., "The cat is not cold").
- **Black**: Neutral premises (e.g., "The dog is round").
2. **Conclusion & Ground Truth**:
- Conclusion: "The cat is not cold."
- Ground Truth Label: **False** (marked in red).
3. **Reasoning Processes**:
- **GPT-3.5-Turbo**:
- 13 steps, including invalid reasoning (e.g., "The cat is not cold" derived from unrelated premises).
- Marked with a red cross for errors.
- **GPT-4**:
- 7 steps, correctly identifying the conclusion as **False** with valid references to premises (e.g., "Premise 17").
- Marked with a green check.
4. **Challenges**:
- **Challenge #1**: Unstructured LLM responses (e.g., GPT-3.5-Turbo’s invalid steps).
- **Challenge #2**: Subtle/silent reasoning errors (e.g., GPT-4’s correct but incomplete reasoning).
### Content Details
- **Premises**:
- Key relationships:
- Bear, cat, dog, and mouse interactions (e.g., "The bear likes the cat," "The mouse visits the dog").
- Conditional logic (e.g., "If something is green...").
- Contradictions: Premise 9 ("The cat visits the mouse") vs. Premise 18 ("If something is cold...").
- **Reasoning Processes**:
- **GPT-3.5-Turbo**:
- Step 13: Incorrectly concludes "The cat is not cold" without valid premise support.
- **GPT-4**:
- Step 7: Correctly identifies the conclusion as **False** using Premise 17 ("If something visits the mouse and the mouse visits the dog...").
### Key Observations
1. **Model Discrepancies**:
- GPT-3.5-Turbo produces unstructured, error-prone reasoning (e.g., Step 7: "Unknown" logic).
- GPT-4 provides structured, accurate reasoning but misses some implicit connections.
2. **Logical Gaps**:
- Premise 17 is critical for the conclusion but is overlooked in GPT-3.5-Turbo’s process.
- Premise 9 ("The cat visits the mouse") conflicts with the conclusion’s validity.
3. **Color Coding**:
- Blue/Red/Black coding aids in tracing conditional vs. factual premises but introduces ambiguity in Step 7 (GPT-3.5-Turbo).
### Interpretation
- **Structured vs. Unstructured Reasoning**:
- GPT-4’s structured approach (referencing specific premises) outperforms GPT-3.5-Turbo’s fragmented logic.
- The conclusion’s falsity hinges on Premise 17, which GPT-3.5-Turbo fails to integrate.
- **Challenges in Logical Tasks**:
- Unstructured responses (Challenge #1) lead to invalid conclusions due to missing premise linkages.
- Subtle errors (Challenge #2) arise when models omit critical premises (e.g., GPT-4’s omission of Premise 9).
- **Implications**:
- Highlights the need for explicit premise referencing in LLM reasoning to avoid errors.
- Demonstrates how color coding and premise numbering can aid or hinder logical clarity.