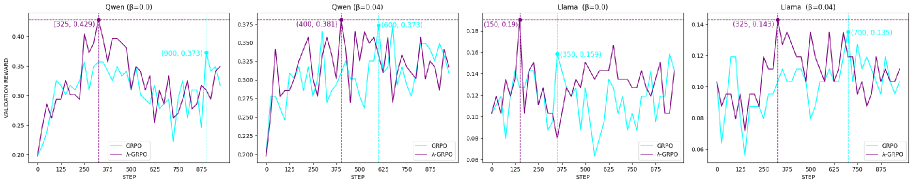
## Line Graphs: Comparison of GRPO and Λ-GRPO Algorithms Across Datasets
### Overview
The image contains four line graphs comparing the validation rewards of two algorithms, **GRPO** (cyan) and **Λ-GRPO** (purple), across different datasets and hyperparameter settings (β values). Each graph represents a distinct dataset and β value, with the x-axis showing training steps (0–800) and the y-axis showing validation reward. Peaks in performance are annotated with coordinates, and legends are positioned in the bottom-right corner of each graph.
---
### Components/Axes
- **X-axis**: Labeled "STEP," ranging from 0 to 800 (steps).
- **Y-axis**: Labeled "VALIDATION REWARD," with scales varying by graph (e.g., 0.20–0.40 for Qwen, 0.06–0.14 for Llama).
- **Legends**: Located in the bottom-right of each graph, with cyan representing **GRPO** and purple representing **Λ-GRPO**.
- **Graph Titles**:
- Top-left: "Qwen (β=0.0)"
- Top-right: "Qwen (β=0.04)"
- Bottom-left: "Llama (β=0.0)"
- Bottom-right: "Llama (β=0.04)"
---
### Detailed Analysis
#### Qwen (β=0.0)
- **GRPO** (cyan): Peaks at **(1900, 0.373)**. The line shows significant fluctuations, with a sharp rise to the peak followed by a decline.
- **Λ-GRPO** (purple): Peaks at **(325, 0.429)**. The line exhibits earlier and sharper peaks compared to GRPO, with higher validation rewards.
#### Qwen (β=0.04)
- **GRPO** (cyan): Peaks at **(600, 0.373)**. The line shows moderate fluctuations, with a peak near the midpoint of the x-axis.
- **Λ-GRPO** (purple): Peaks at **(400, 0.381)**. Slightly higher reward than GRPO, with a peak slightly later than GRPO.
#### Llama (β=0.0)
- **GRPO** (cyan): Peaks at **(350, 0.159)**. The line shows moderate fluctuations, with a peak near the midpoint.
- **Λ-GRPO** (purple): Peaks at **(325, 0.143)**. Slightly lower reward than GRPO, with a peak slightly earlier.
#### Llama (β=0.04)
- **GRPO** (cyan): Peaks at **(700, 0.135)**. The line shows late-stage fluctuations, with a peak near the end of the x-axis.
- **Λ-GRPO** (purple): Peaks at **(325, 0.143)**. Slightly higher reward than GRPO, with a peak earlier in training.
---
### Key Observations
1. **Peak Timing**:
- Λ-GRPO often peaks earlier than GRPO (e.g., Qwen β=0.0: 325 vs. 1900 steps).
- GRPO sometimes achieves higher rewards later in training (e.g., Qwen β=0.04: 600 steps vs. Λ-GRPO’s 400 steps).
2. **Reward Magnitude**:
- Λ-GRPO outperforms GRPO in Qwen β=0.0 (0.429 vs. 0.373).
- GRPO matches or exceeds Λ-GRPO in other cases (e.g., Qwen β=0.04: 0.373 vs. 0.381).
3. **Fluctuations**: Both algorithms exhibit high volatility in validation rewards, suggesting sensitivity to hyperparameters or training dynamics.
---
### Interpretation
The data suggests that the choice between GRPO and Λ-GRPO depends on the dataset and β value:
- **Λ-GRPO** excels in Qwen β=0.0, achieving higher rewards earlier, but underperforms in Qwen β=0.04.
- **GRPO** shows better late-stage performance in Qwen β=0.04 and Llama β=0.04, indicating potential robustness in later training phases.
- The β parameter (likely a regularization or learning rate factor) significantly influences algorithm effectiveness, with Λ-GRPO favoring lower β values (e.g., Qwen β=0.0) and GRPO performing better at higher β (e.g., Llama β=0.04).
The annotations and peak coordinates highlight critical inflection points, emphasizing the need for careful hyperparameter tuning. The visual trends align with the numerical data, confirming that Λ-GRPO’s early peaks and GRPO’s late-stage gains are consistent across datasets.