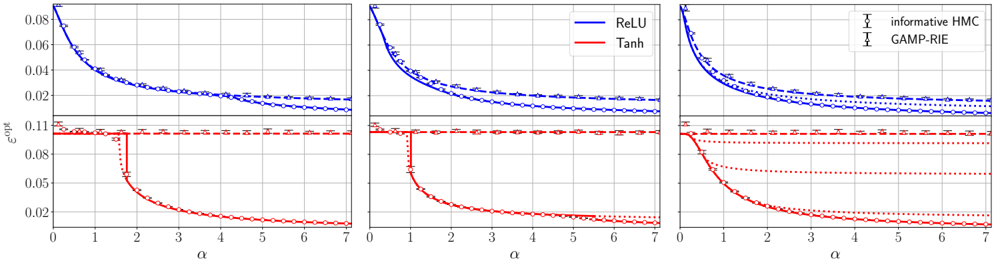
## Chart: Comparison of ReLU and Tanh Activation Functions with Different Methods
### Overview
The image presents three line charts comparing the performance of ReLU (Rectified Linear Unit) and Tanh (Hyperbolic Tangent) activation functions under different conditions. The charts share the same x-axis, labeled "α", and y-axis, labeled "εopt". Each chart represents a different method (informative HMC and GAMP-RIE). The performance is evaluated based on the error rate, with lower values indicating better performance.
### Components/Axes
* **X-axis:** "α" - Ranges from 0 to 7, with tick marks at every integer value.
* **Y-axis:** "εopt" - Ranges from 0.02 to 0.08 in the top half of the chart and 0.02 to 0.11 in the bottom half of the chart.
* **Legend (Top-Right):**
* Blue Line: ReLU
* Red Line: Tanh
* Informative HMC: Error bars with circles
* GAMP-RIE: Error bars with horizontal bars
### Detailed Analysis
Each of the three charts displays two sets of curves: one for ReLU (blue) and one for Tanh (red). Each set contains three curves: a solid line, a dashed line, and a dotted line. The solid and dashed lines have error bars.
**Chart 1 (Left):**
* **ReLU (Blue):** The solid blue line with circular error bars (informative HMC) starts at approximately 0.08 at α=0 and decreases to approximately 0.02 at α=7. The dashed blue line with horizontal error bars (GAMP-RIE) starts at approximately 0.07 at α=0 and decreases to approximately 0.02 at α=7. The dotted blue line starts at approximately 0.06 at α=0 and decreases to approximately 0.02 at α=7.
* **Tanh (Red):** The solid red line with circular error bars (informative HMC) starts at approximately 0.11 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7. The dashed red line with horizontal error bars (GAMP-RIE) remains constant at approximately 0.105 from α=0 to α=7. The dotted red line starts at approximately 0.10 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7.
**Chart 2 (Middle):**
* **ReLU (Blue):** The solid blue line with circular error bars (informative HMC) starts at approximately 0.08 at α=0 and decreases to approximately 0.02 at α=7. The dashed blue line with horizontal error bars (GAMP-RIE) starts at approximately 0.07 at α=0 and decreases to approximately 0.02 at α=7. The dotted blue line starts at approximately 0.06 at α=0 and decreases to approximately 0.02 at α=7.
* **Tanh (Red):** The solid red line with circular error bars (informative HMC) starts at approximately 0.11 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7. The dashed red line with horizontal error bars (GAMP-RIE) remains constant at approximately 0.105 from α=0 to α=7. The dotted red line starts at approximately 0.10 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7.
**Chart 3 (Right):**
* **ReLU (Blue):** The solid blue line with circular error bars (informative HMC) starts at approximately 0.08 at α=0 and decreases to approximately 0.02 at α=7. The dashed blue line with horizontal error bars (GAMP-RIE) starts at approximately 0.07 at α=0 and decreases to approximately 0.02 at α=7. The dotted blue line starts at approximately 0.06 at α=0 and decreases to approximately 0.02 at α=7.
* **Tanh (Red):** The solid red line with circular error bars (informative HMC) starts at approximately 0.11 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7. The dashed red line with horizontal error bars (GAMP-RIE) remains constant at approximately 0.105 from α=0 to α=7. The dotted red line starts at approximately 0.10 at α=0, drops sharply to approximately 0.05 at α=1.5, and then decreases to approximately 0.02 at α=7.
### Key Observations
* **ReLU Performance:** The ReLU activation function consistently shows a decreasing error rate as α increases across all three charts.
* **Tanh Performance:** The Tanh activation function exhibits a sharp drop in error rate around α=1.5 when using the solid line with circular error bars (informative HMC) and the dotted line. The dashed line with horizontal error bars (GAMP-RIE) remains relatively constant.
* **Error Bar Placement:** The error bars are placed vertically on the solid and dashed lines.
* **Chart Similarity:** The three charts are nearly identical.
### Interpretation
The charts suggest that the ReLU activation function generally performs better than the Tanh activation function, especially at lower values of α. The sharp drop in error rate for Tanh around α=1.5 indicates a critical point where the function's behavior changes significantly. The consistent performance of ReLU across different values of α suggests it might be a more stable choice in these scenarios. The dashed line with horizontal error bars (GAMP-RIE) for Tanh shows a constant error rate, indicating that this method might not be as effective for the Tanh activation function. The similarity of the three charts suggests that the underlying conditions being varied between the charts have little impact on the relative performance of ReLU and Tanh.