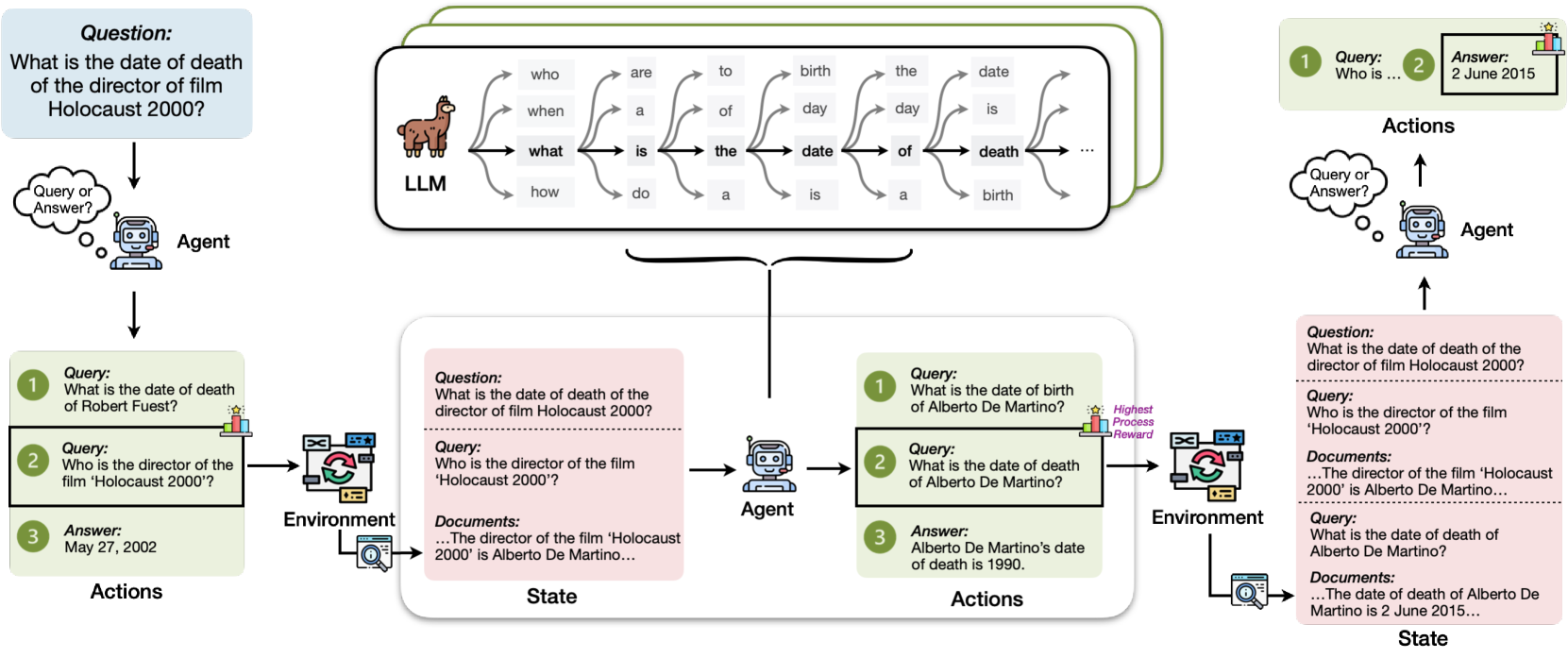
## Flowchart: Agent-Environment-State Interaction with LLM
### Overview
The diagram illustrates a system where an **Agent** interacts with an **Environment** to answer questions, updating a **State** through a **Language Learning Model (LLM)**. The flow includes queries, document retrieval, and process rewards. Key elements include text boxes for questions/answers, arrows indicating information flow, and a central LLM with linguistic decomposition.
### Components/Axes
- **Agent**: A robot icon with a speech bubble labeled "Query or Answer?"
- **Environment**: A computer screen with a magnifying glass, representing document retrieval.
- **State**: A white box containing text about the director and date of death.
- **LLM**: A llama icon with arrows labeled "who," "when," "what," "how," and linguistic terms (e.g., "is," "the," "date," "death").
- **Process Reward**: A star icon with a "Highest Process Reward" label.
### Detailed Analysis
#### Textual Content
1. **Central LLM**:
- Arrows from the llama icon point to linguistic terms:
- "who" → "are" → "a" → "do"
- "when" → "to" → "birth" → "day"
- "what" → "is" → "the" → "date"
- "how" → "of" → "death" → "birth"
2. **Queries and Answers**:
- **Query 1**: "What is the date of death of the director of film Holocaust 2000?"
- **Answer**: "May 27, 2002" (incorrect, as per later correction).
- **Query 2**: "Who is the director of the film 'Holocaust 2000'?"
- **Answer**: "Alberto De Martino" (correct).
- **Query 3**: "What is the date of death of Alberto De Martino?"
- **Answer**: "1990" (correct).
3. **Process Reward**:
- A star icon with "Highest Process Reward" label, indicating optimal performance.
#### Spatial Grounding
- **Top**: Central LLM (llama icon) with linguistic decomposition.
- **Left**: Agent (robot) with query/answer flow.
- **Right**: Environment (computer screen) and State (text box).
- **Bottom**: Process reward and feedback loop.
### Key Observations
- The diagram shows a **feedback loop**: The Agent asks a question, the Environment provides documents, the State updates, and the Agent answers.
- **Inconsistencies**:
- Initial answer for the director’s death date is "May 27, 2002" (incorrect).
- Corrected answer is "1990" (from the State).
- **Color Coding**:
- LLM: Brown (llama icon).
- Agent: Blue (robot).
- Environment: Green (computer screen).
- State: White (text box).
### Interpretation
The diagram represents a **question-answering system** where the Agent uses an LLM to decompose queries into linguistic components, retrieves documents from the Environment, and updates the State with answers. The process reward suggests optimization for accuracy. The example highlights a correction in the director’s death date, emphasizing the system’s ability to refine answers through iterative interactions. The LLM’s role in breaking down queries into linguistic elements (e.g., "who," "when," "what") underscores its function in natural language processing.
## Notes
- **Language**: English (primary), with no other languages present.
- **Data Structure**: No numerical data or tables; relies on textual queries and answers.
- **Trends**: The flow emphasizes **information retrieval** and **state updates** rather than numerical trends.