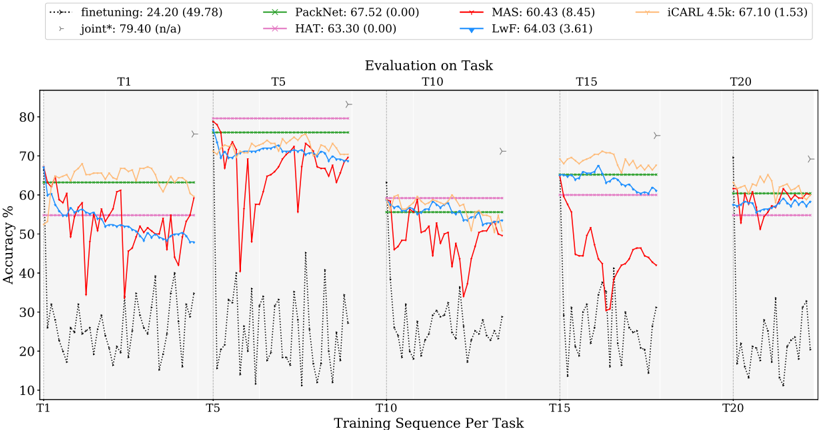
## Line Chart: Evaluation on Task
### Overview
The image is a line chart comparing the performance of different continual learning methods across multiple tasks (T1, T5, T10, T15, T20). The chart displays the accuracy percentage of each method as the training sequence progresses per task. The methods compared are finetuning, joint*, PackNet, HAT, MAS, LwF, and iCARL 4.5k.
### Components/Axes
* **Title:** Evaluation on Task
* **X-axis:** Training Sequence Per Task (T1, T5, T10, T15, T20)
* **Y-axis:** Accuracy % (ranging from 10% to 80%)
* **Legend (Top-Left):**
* finetuning (black dotted line): 24.20 (49.78)
* joint* (gray triangle marker): 79.40 (n/a)
* PackNet (green line with x markers): 67.52 (0.00)
* HAT (pink line with x markers): 63.30 (0.00)
* MAS (red line): 60.43 (8.45)
* LwF (blue line): 64.03 (3.61)
* iCARL 4.5k (orange line): 67.10 (1.53)
### Detailed Analysis
**finetuning (black dotted line):**
* The finetuning line fluctuates significantly within each task sequence.
* T1: Starts around 65%, drops sharply, and oscillates between 15% and 35%.
* T5: Oscillates between 15% and 40%.
* T10: Oscillates between 20% and 30%.
* T15: Oscillates between 20% and 30%.
* T20: Oscillates between 20% and 30%.
* Average: 24.20 (49.78)
**joint* (gray triangle marker):**
* The joint* method is represented by a gray triangle marker at the top of each task.
* T1: Approximately 79.40
* T5: Approximately 79.40
* T10: Approximately 79.40
* T15: Approximately 79.40
* T20: Approximately 79.40
* Average: 79.40 (n/a)
**PackNet (green line with x markers):**
* The PackNet line remains relatively stable across all tasks.
* T1: Starts around 63%.
* T5: Stays around 77%.
* T10: Stays around 60%.
* T15: Stays around 67%.
* T20: Stays around 67%.
* Average: 67.52 (0.00)
**HAT (pink line with x markers):**
* The HAT line remains relatively stable across all tasks.
* T1: Starts around 55%.
* T5: Stays around 80%.
* T10: Stays around 60%.
* T15: Stays around 60%.
* T20: Stays around 60%.
* Average: 63.30 (0.00)
**MAS (red line):**
* The MAS line fluctuates significantly within each task sequence.
* T1: Starts around 70%, drops sharply, and oscillates between 30% and 60%.
* T5: Drops sharply to 20% and then oscillates between 30% and 75%.
* T10: Oscillates between 20% and 60%.
* T15: Drops sharply to 10% and then oscillates between 20% and 50%.
* T20: Oscillates between 50% and 60%.
* Average: 60.43 (8.45)
**LwF (blue line):**
* The LwF line remains relatively stable across all tasks.
* T1: Starts around 70%, then decreases to 50%.
* T5: Stays around 72%.
* T10: Stays around 58%.
* T15: Stays around 65%.
* T20: Stays around 60%.
* Average: 64.03 (3.61)
**iCARL 4.5k (orange line):**
* The iCARL 4.5k line remains relatively stable across all tasks.
* T1: Starts around 65%.
* T5: Stays around 75%.
* T10: Stays around 55%.
* T15: Stays around 70%.
* T20: Stays around 65%.
* Average: 67.10 (1.53)
### Key Observations
* The 'joint*' method consistently achieves the highest accuracy across all tasks.
* The 'finetuning' method shows significant fluctuations and generally lower accuracy compared to other methods.
* The 'MAS' method also exhibits significant fluctuations.
* 'PackNet', 'HAT', 'LwF', and 'iCARL 4.5k' methods show more stable performance across different tasks.
### Interpretation
The chart illustrates the performance of different continual learning methods when evaluated on a sequence of tasks. The 'joint*' method, which likely represents a scenario where the model is trained on all tasks simultaneously, serves as an upper bound for performance. The 'finetuning' method, which involves simply training the model on each new task without any specific continual learning strategy, suffers from catastrophic forgetting, leading to fluctuating and generally lower accuracy. The other methods ('PackNet', 'HAT', 'MAS', 'LwF', and 'iCARL 4.5k') represent different approaches to mitigate catastrophic forgetting, and their performance varies depending on the task sequence. 'MAS' appears to be more volatile than 'PackNet', 'HAT', 'LwF', and 'iCARL 4.5k'. The stability of 'PackNet', 'HAT', 'LwF', and 'iCARL 4.5k' suggests that these methods are more effective at retaining knowledge from previous tasks while learning new ones.