\n
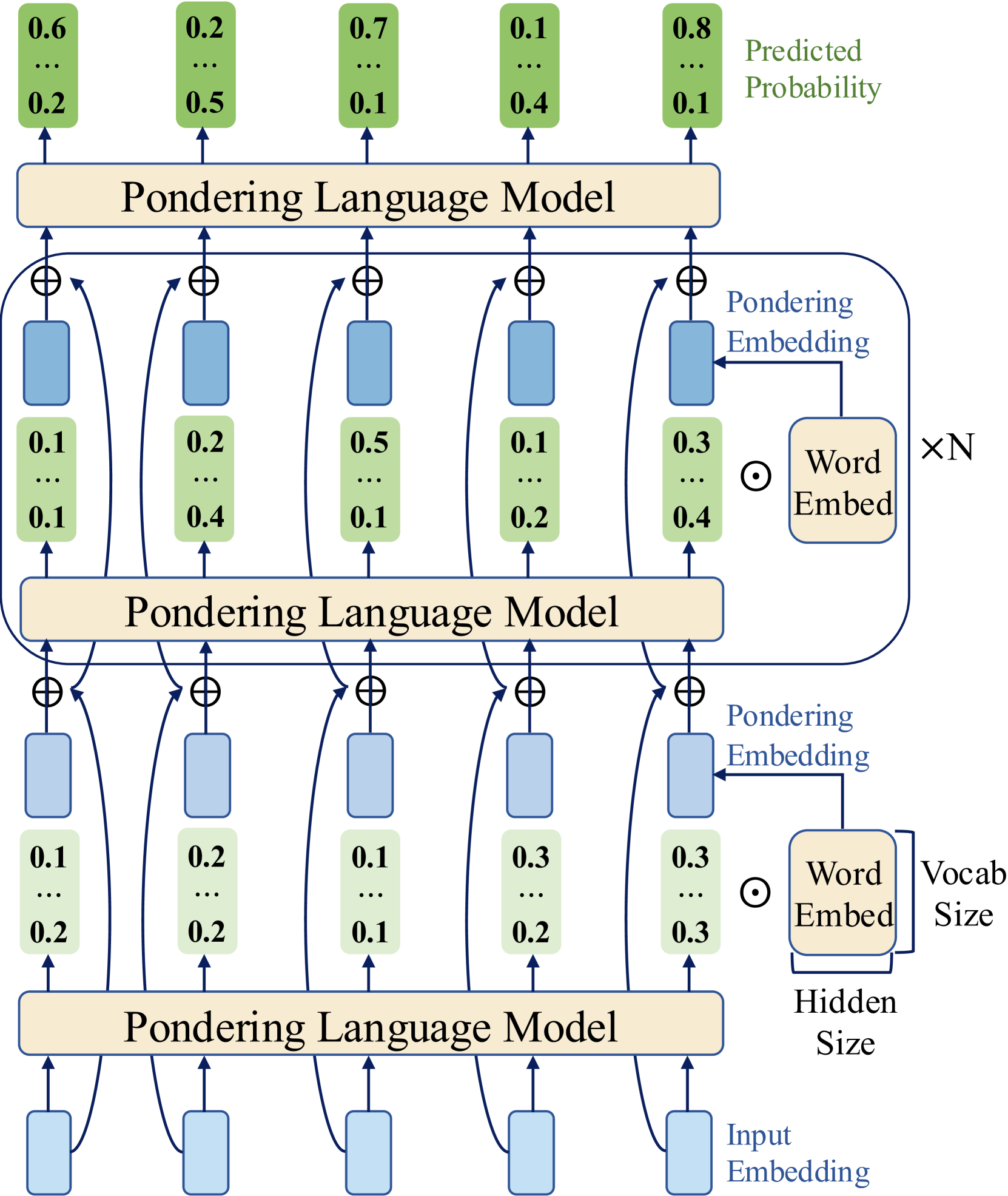
## Diagram: Pondering Language Model Architecture
### Overview
The image depicts a diagram illustrating the architecture of a "Pondering Language Model". It shows a stacked arrangement of three identical "Pondering Language Model" blocks, each processing input embeddings and generating predicted probabilities. The diagram highlights the flow of data through these blocks, emphasizing the use of "Pondering Embeddings" and "Word Embeddings" at various stages.
### Components/Axes
The diagram consists of the following key components:
* **Pondering Language Model:** Represented as rectangular blocks, these are the core processing units. There are three stacked instances.
* **Input Embedding:** The initial layer, providing input to the first "Pondering Language Model" block.
* **Word Embed:** Represented by circles with a plus sign inside, these are used within each "Pondering Language Model" block.
* **Pondering Embedding:** Represented by light blue rectangles, these are also used within each "Pondering Language Model" block.
* **Predicted Probability:** The output layer, displaying probability values.
* **Labels:** "Pondering Language Model", "Pondering Embedding", "Word Embed", "Input Embedding", "Predicted Probability", "xN", "Vocab Size", "Hidden Size".
* **Numerical Values:** Probability values are displayed within green and yellow rectangles at various points in the diagram.
### Detailed Analysis or Content Details
The diagram shows a three-layer architecture. Let's analyze each layer:
**Layer 1 (Bottom):**
* **Input Embedding:** Four input embeddings are shown.
* **Pondering Language Model:** The input embeddings feed into a "Pondering Language Model" block.
* **Word Embed:** Each input embedding is connected to a "Word Embed" component.
* **Pondering Embedding:** Each "Word Embed" is connected to a "Pondering Embedding" component.
* **Output:** The output of this layer consists of five values: 0.1, 0.2, 0.1, 0.3, 0.3. These values are displayed within green and yellow rectangles.
**Layer 2 (Middle):**
* **Pondering Language Model:** This layer receives input from the previous layer's "Pondering Language Model" block.
* **Word Embed:** Similar to Layer 1, each input is connected to a "Word Embed" component.
* **Pondering Embedding:** Each "Word Embed" is connected to a "Pondering Embedding" component.
* **Output:** The output of this layer consists of five values: 0.1, 0.2, 0.5, 0.1, 0.2. These values are displayed within green and yellow rectangles.
**Layer 3 (Top):**
* **Pondering Language Model:** This layer receives input from the previous layer's "Pondering Language Model" block.
* **Output:** The output of this layer is the "Predicted Probability", consisting of five values: 0.6, 0.2, 0.7, 0.1, 0.8. These values are displayed within green and yellow rectangles.
* **Additional Probabilities:** Below the predicted probabilities, there are additional values: 0.2, 0.5, 0.1, 0.4, 0.1.
**Annotations:**
* **xN:** Located near the "Word Embed" component, likely indicating the number of word embeddings.
* **Vocab Size:** Located near the "Word Embed" component, indicating the vocabulary size.
* **Hidden Size:** Located near the "Pondering Language Model" block, indicating the hidden size.
The connections between components are indicated by arrows. The plus sign within the "Word Embed" circles suggests an addition operation. The circles with the plus sign are connected to the rectangles representing the "Pondering Embeddings".
### Key Observations
* The architecture is repetitive, with three identical "Pondering Language Model" blocks stacked on top of each other.
* The probability values at the output layer ("Predicted Probability") are generally higher than the intermediate values.
* The diagram emphasizes the interplay between "Word Embeddings" and "Pondering Embeddings" within each layer.
* The values within the green and yellow rectangles appear to represent probabilities or activations.
### Interpretation
The diagram illustrates a deep learning architecture designed for language modeling. The "Pondering Language Model" blocks likely represent recurrent neural network (RNN) or transformer layers. The "Word Embeddings" convert words into vector representations, while the "Pondering Embeddings" might represent attention mechanisms or other contextual information. The stacking of these layers allows the model to learn hierarchical representations of language, ultimately predicting the probability of the next word or sequence of words.
The use of "Pondering Embeddings" suggests a mechanism for the model to focus on relevant parts of the input sequence. The numerical values represent the model's internal state and predictions at different stages of processing. The diagram provides a high-level overview of the architecture, without specifying the exact details of the layer implementations. The "xN", "Vocab Size", and "Hidden Size" annotations provide information about the model's dimensions and capacity. The diagram suggests a model capable of processing sequential data and generating probabilistic outputs, making it suitable for tasks such as text generation, machine translation, or sentiment analysis.