TECHNICAL ASSET FINGERPRINT
c0c8f8187ca189852fe94697
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
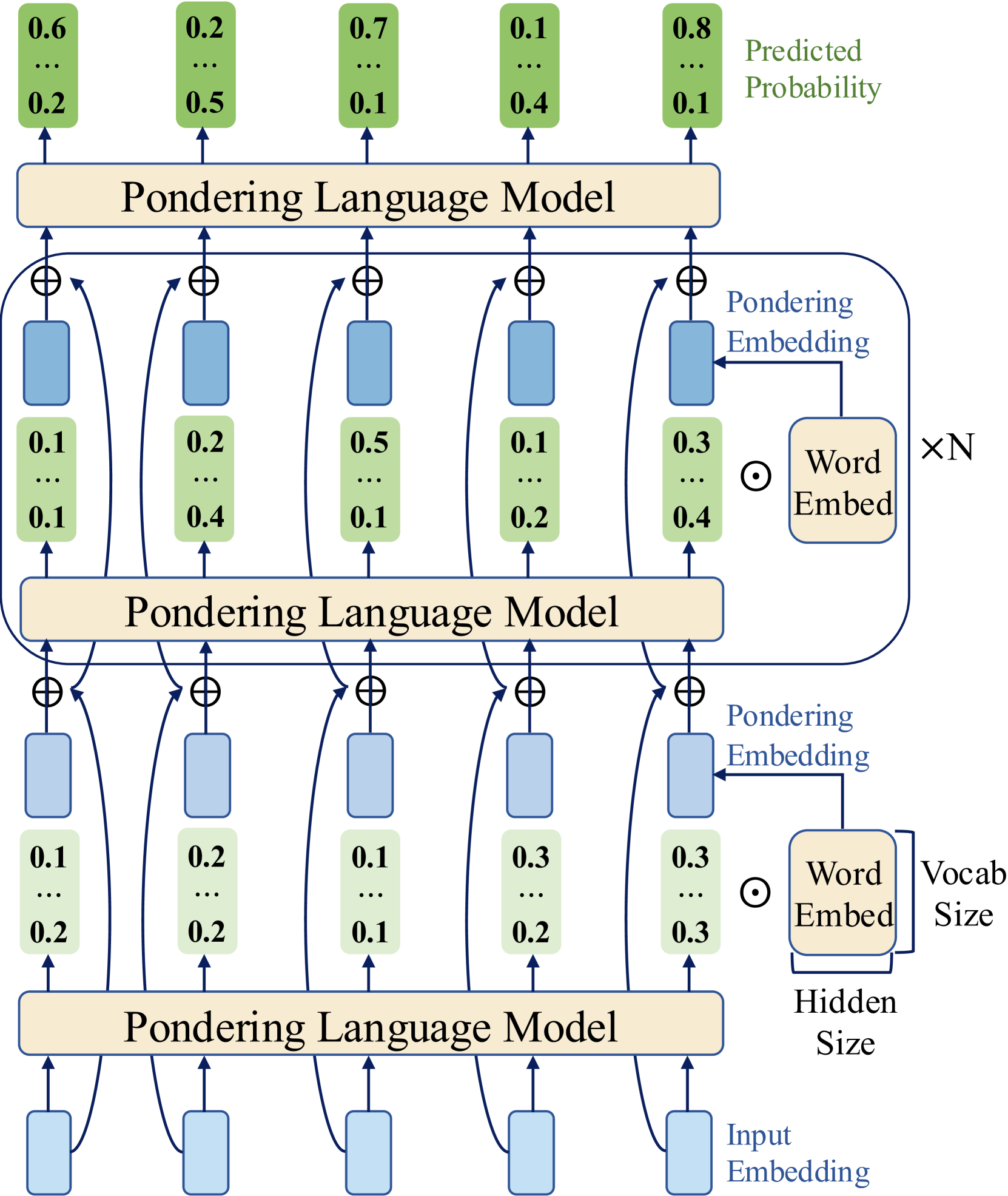
## Diagram: Pondering Language Model Architecture
### Overview
This image is a technical architecture diagram illustrating a multi-layer neural network model called a "Pondering Language Model." The diagram depicts a hierarchical, recurrent processing structure where information flows from bottom to top through repeated computational blocks. The model processes input embeddings through multiple stages, each involving a "Pondering Language Model" block, to ultimately produce a set of predicted probability distributions.
### Components/Axes
The diagram is organized into three primary vertical layers or stages, each centered around a "Pondering Language Model" block. The flow is bottom-up.
**1. Input Layer (Bottom):**
* **Component:** Five light blue vertical rectangles.
* **Label:** "Input Embedding" (text located to the right of the bottom-most rectangle).
* **Function:** These represent the initial vector representations of input tokens.
**2. First Processing Stage (Bottom-Middle):**
* **Central Block:** A beige horizontal rectangle labeled "Pondering Language Model".
* **Input:** Receives arrows from the five "Input Embedding" rectangles below.
* **Output:** Produces five outputs, each split into two paths:
* **Path A (Direct):** An arrow goes upward to a ⊕ (addition/concatenation) symbol.
* **Path B (Via Embedding):** An arrow goes to a light green vertical rectangle containing a vector of numbers (e.g., "0.1 ... 0.2"). This green rectangle is then fed into a blue rectangle above it.
* **Associated Components (Right Side):**
* A beige box labeled "Word Embed" with dimensions indicated: "Vocab Size" (vertical) and "Hidden Size" (horizontal).
* A circle with a dot (⊙) symbol, likely representing an element-wise operation or selection.
* An arrow labeled "Pondering Embedding" points from the "Word Embed" box to the blue rectangle in the path above the green vector.
**3. Second Processing Stage (Middle, within a rounded rectangle):**
* **Enclosure:** A large, light blue rounded rectangle encloses this entire stage, labeled "×N" on the right, indicating this block is repeated N times.
* **Central Block:** Another "Pondering Language Model" block.
* **Input:** Receives combined signals from the ⊕ symbols below it. Each ⊕ combines:
* The direct output from the previous "Pondering Language Model" block.
* The output from the blue rectangle (which processed the green vector via the "Pondering Embedding").
* **Output:** Similar split as the first stage: direct path to a ⊕ above, and a path through a green vector/blue rectangle pair.
* **Associated Components (Right Side):** Identical "Word Embed" and "Pondering Embedding" structure as in the first stage.
**4. Final Processing Stage (Top):**
* **Central Block:** A third "Pondering Language Model" block.
* **Input:** Receives combined signals from the ⊕ symbols of the second stage.
* **Output:** Five final outputs, each leading to a green vertical rectangle at the very top.
**5. Output Layer (Top):**
* **Component:** Five green vertical rectangles.
* **Label:** "Predicted Probability" (text located to the right of the top-right rectangle).
* **Content:** Each rectangle contains a vector of numbers representing a probability distribution. From left to right, the visible top and bottom values are:
1. Top: `0.6`, Bottom: `0.2`
2. Top: `0.2`, Bottom: `0.5`
3. Top: `0.7`, Bottom: `0.1`
4. Top: `0.1`, Bottom: `0.4`
5. Top: `0.8`, Bottom: `0.1`
* The ellipsis (`...`) in each box indicates additional probability values are present but not shown.
### Detailed Analysis
**Data Flow and Operations:**
1. **Bottom-Up Propagation:** Information starts as "Input Embedding" vectors at the bottom.
2. **Pondering Transformation:** Each "Pondering Language Model" block transforms its input. The diagram suggests this block produces two outputs: one for immediate combination (via ⊕) and one that is further processed into a "Pondering Embedding."
3. **Embedding Integration:** The "Pondering Embedding" is derived from a "Word Embed" matrix (of size Vocab Size × Hidden Size) and is used to modulate or augment the representation before it is combined with the direct path at the next ⊕ node.
4. **Recurrence/Iteration:** The "×N" label around the middle stage is critical. It indicates that the core processing loop—consisting of the "Pondering Language Model" block, the generation of a "Pondering Embedding," and the combination at the ⊕ node—is repeated N times. This suggests an iterative "pondering" or reasoning process over the same intermediate representations.
5. **Final Prediction:** After N iterations (or through the final layer), the model outputs five separate probability distributions, likely corresponding to predictions for five positions or tokens in a sequence.
**Spatial Grounding:**
* The "Predicted Probability" label is in the top-right corner.
* The "Word Embed" and dimension labels ("Vocab Size", "Hidden Size") are anchored to the right side of the diagram, aligned with their respective processing stages.
* The "×N" label is positioned to the right of the rounded rectangle enclosing the repeated middle stage.
* The ⊕ symbols are consistently placed above each blue rectangle in the processing path, acting as junction points.
### Key Observations
1. **Structured Repetition:** The architecture is highly modular, built from repeating identical "Pondering Language Model" units. The "×N" notation explicitly highlights an iterative computational process.
2. **Dual-Path Processing:** Each stage features a split where information takes a direct path and a parallel path that involves a learned "Pondering Embedding." These paths are recombined, suggesting a mechanism for integrating different types of processed information.
3. **Probabilistic Output:** The final layer consists of probability distributions, confirming this is a predictive model, likely for language modeling or a similar sequence prediction task.
4. **Dimensionality Indicators:** The "Word Embed" box explicitly notes the matrix dimensions ("Vocab Size" x "Hidden Size"), providing a key technical detail about the model's capacity.
5. **Visual Abstraction:** The diagram uses consistent color coding (beige for core model blocks, light blue for embeddings/hidden states, green for probability vectors) and symbols (⊕ for combination, ⊙ for an operation with the Word Embed) to convey complex operations abstractly.
### Interpretation
This diagram illustrates a **"Pondering" or iterative refinement architecture** for a language model. The core innovation appears to be the introduction of a dedicated "Pondering Embedding" that is generated and integrated at each step of a multi-stage (or recurrent) process.
* **What it suggests:** The model doesn't just process input in a single forward pass. Instead, it engages in an internal, iterative loop (the "×N" stage) where it repeatedly applies its "Pondering Language Model" and updates its internal state using a specialized embedding. This mimics a form of "thinking" or deliberation before making a final prediction.
* **Relationships:** The "Word Embed" serves as a static knowledge base (the vocabulary). The "Pondering Embedding" is a dynamic, context-dependent vector derived from this base at each step, allowing the model to selectively focus on or reason about different aspects of its vocabulary during the pondering phase. The ⊕ nodes are critical fusion points where the direct processing stream and the pondering-augmented stream are merged.
* **Anomalies/Notable Points:** The presence of five parallel input/output streams is notable. This could represent a fixed-width sequence processing model (e.g., processing five tokens at a time) or five separate prediction heads. The specific numerical values in the probability vectors (e.g., `[0.6, ..., 0.2]`) are illustrative examples and not interpretable without knowing the corresponding token vocabulary.
**In essence, the diagram depicts a language model augmented with an explicit, learnable mechanism for iterative internal reasoning ("pondering") before committing to a final output probability distribution.**
DECODING INTELLIGENCE...