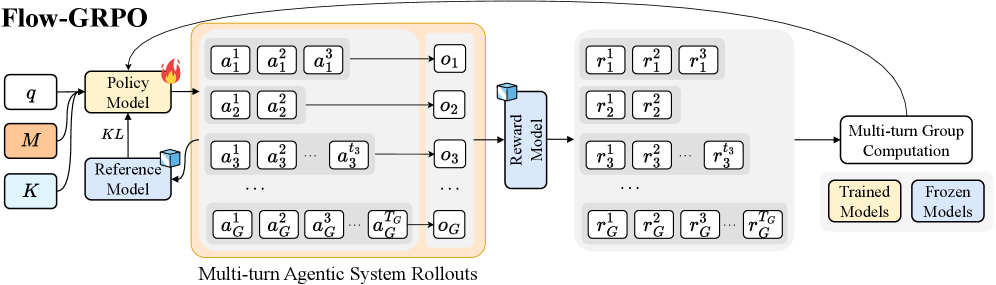
## Diagram: Flow-GRPO Architecture
### Overview
The image is a diagram illustrating the architecture of a system called Flow-GRPO. It depicts the flow of information and processes involved in multi-turn agentic system rollouts, reward modeling, and group computation. The diagram includes components such as Policy Model, Reference Model, Reward Model, and Multi-turn Group Computation, along with representations of actions, observations, and rewards.
### Components/Axes
* **Title:** Flow-GRPO (top-left)
* **Input Parameters (Left):**
* `q` (white box)
* `M` (orange box)
* `K` (light blue box)
* **Models:**
* `Policy Model` (orange box, top-center): Receives input from `q` and `Reference Model`. Has a fire icon on the top-right.
* `Reference Model` (light blue box, bottom-center): Receives input from `q`. Sends output to `Policy Model` via `KL`.
* `Reward Model` (light blue box, center-right): Receives input from the "Multi-turn Agentic System Rollouts".
* **Multi-turn Agentic System Rollouts (Center):**
* Enclosed in an orange rounded rectangle.
* Contains multiple rows, each representing a rollout.
* Each row contains action sequences `a_i^1`, `a_i^2`, `a_i^3`, ..., `a_i^{t_G}` and an observation `o_i`.
* The index `i` ranges from 1 to G (e.g., `a_1^1`, `a_2^1`, `a_3^1`, ..., `a_G^1`).
* **Rewards (Right):**
* Enclosed in a light gray rounded rectangle.
* Contains multiple rows, each corresponding to a rollout.
* Each row contains reward sequences `r_i^1`, `r_i^2`, `r_i^3`, ..., `r_i^{t_G}`.
* The index `i` ranges from 1 to G (e.g., `r_1^1`, `r_2^1`, `r_3^1`, ..., `r_G^1`).
* **Multi-turn Group Computation (Bottom-Right):** A white box with rounded corners. Receives input from the "Rewards" section and sends feedback to the "Policy Model".
* **Legend (Bottom-Right):**
* `Trained Models` (orange box)
* `Frozen Models` (light blue box)
### Detailed Analysis or Content Details
* **Flow of Information:**
* The `Policy Model` receives inputs `q` and feedback from the `Reference Model` (via `KL`).
* The `Policy Model` generates actions that are part of the "Multi-turn Agentic System Rollouts".
* The rollouts produce observations `o_i`.
* The `Reward Model` takes the rollouts as input and generates rewards `r_i^j`.
* The rewards are used in "Multi-turn Group Computation".
* The "Multi-turn Group Computation" provides feedback to the `Policy Model`.
* **Action and Reward Sequences:**
* Actions are represented as `a_i^j`, where `i` is the rollout index and `j` is the time step.
* Rewards are represented as `r_i^j`, where `i` is the rollout index and `j` is the time step.
* **Models:**
* The `Policy Model` is marked with a fire icon, possibly indicating active training or optimization.
* The `Reference Model` provides a baseline or comparison for the `Policy Model`.
* The `Reward Model` evaluates the performance of the agentic system.
### Key Observations
* The diagram illustrates a closed-loop system where the `Policy Model` generates actions, the environment provides rewards, and the `Policy Model` is updated based on these rewards.
* The "Multi-turn Agentic System Rollouts" represent the interaction of multiple agents over multiple time steps.
* The `KL` divergence is used to regulate the `Policy Model` with respect to the `Reference Model`.
* The legend indicates the presence of both trained and frozen models within the system.
### Interpretation
The Flow-GRPO architecture appears to be a reinforcement learning framework designed for multi-agent systems. The `Policy Model` learns to generate optimal actions through interaction with the environment, guided by a `Reference Model` and evaluated by a `Reward Model`. The "Multi-turn Group Computation" likely involves aggregating rewards across multiple agents and time steps to provide a comprehensive evaluation signal. The use of `KL` divergence suggests a regularization technique to prevent the `Policy Model` from deviating too far from the `Reference Model`. The distinction between trained and frozen models implies a modular design where certain components can be fixed while others are actively learned.