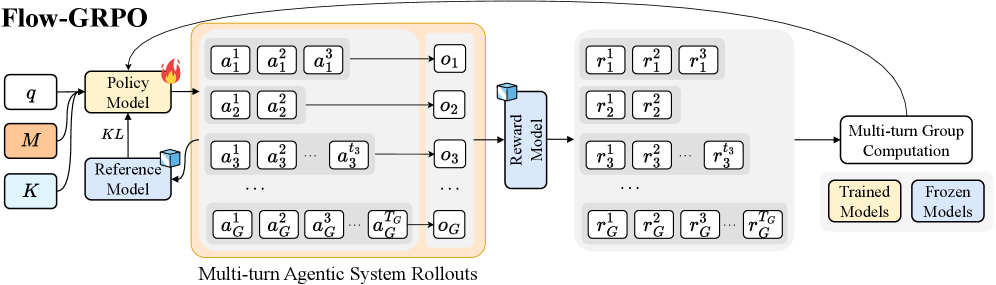
\n
## Technical Diagram: Flow-GRPO Architecture
### Overview
The image displays a technical flowchart titled "Flow-GRPO," illustrating a machine learning training pipeline for a multi-turn agentic system. The diagram shows the flow of data from initial inputs through policy and reference models, generating multi-turn rollouts, which are then scored by a reward model to facilitate group-based computation for model updates.
### Components/Axes
The diagram is organized into several distinct, connected regions:
1. **Input Block (Leftmost):**
* Three input boxes labeled: `q`, `M`, and `K`.
* `M` is highlighted with an orange background.
2. **Model Block (Center-Left):**
* **Policy Model:** A yellow box with a flame icon (indicating a "Trained Model").
* **Reference Model:** A blue box with a cube icon (indicating a "Frozen Model").
* A bidirectional arrow labeled `KL` connects the Policy Model and Reference Model.
3. **Multi-turn Agentic System Rollouts (Center):**
* A large, light-orange container with this title at the bottom.
* It contains multiple rows, each representing a rollout sequence for an agent or group (indexed by `G`).
* Each row consists of a series of action boxes (`a`) leading to an observation box (`o`).
* **Row Structure:**
* Row 1: `a₁¹`, `a₁²`, `a₁³` → `o₁`
* Row 2: `a₂¹`, `a₂²` → `o₂`
* Row 3: `a₃¹`, `a₃²`, ..., `a₃^{t₃}` → `o₃`
* Ellipsis (`...`) indicating intermediate rows.
* Final Row: `a_G¹`, `a_G²`, `a_G³`, ..., `a_G^{t_G}` → `o_G`
4. **Reward Model Block (Center-Right):**
* A blue box labeled "Reward Model" with a cube icon (Frozen Model).
* It receives input from all observation boxes (`o₁` through `o_G`).
5. **Reward Output Block (Right of Reward Model):**
* A large, light-gray container.
* It contains multiple rows of reward values (`r`), corresponding to the actions in the rollouts.
* **Row Structure:**
* Row 1: `r₁¹`, `r₁²`, `r₁³`
* Row 2: `r₂¹`, `r₂²`
* Row 3: `r₃¹`, `r₃²`, ..., `r₃^{t₃}`
* Ellipsis (`...`).
* Final Row: `r_G¹`, `r_G²`, `r_G³`, ..., `r_G^{t_G}`
6. **Computation & Output Block (Rightmost):**
* A box labeled "Multi-turn Group Computation".
* An arrow points from the Reward Output Block to this computation box.
* Two output boxes emerge from the computation:
* "Trained Models" (yellow background).
* "Frozen Models" (blue background).
7. **Legend (Bottom-Right):**
* A small box explaining the iconography:
* Yellow box with flame icon: "Trained Models"
* Blue box with cube icon: "Frozen Models"
8. **Global Flow Arrow:**
* A large, curved arrow originates from the "Multi-turn Group Computation" box and points back to the "Policy Model," indicating an iterative training loop.
### Detailed Analysis
* **Data Flow:** The process begins with inputs `q`, `M`, `K`. The Policy Model (trained) and Reference Model (frozen) interact via a KL divergence constraint. The Policy Model generates multi-turn action sequences (`a`) for `G` different agents or groups, resulting in observations (`o`).
* **Rollout Structure:** The number of actions per rollout varies. Agent 1 has 3 actions, Agent 2 has 2 actions, Agent 3 has `t₃` actions, and the G-th agent has `t_G` actions. This indicates a flexible, multi-turn environment.
* **Reward Assignment:** The frozen Reward Model evaluates each observation (`o`) and assigns a reward (`r`) to *each individual action* within the sequence. The reward structure mirrors the action structure exactly (e.g., `a₁¹` receives reward `r₁¹`).
* **Group Computation:** Rewards from all agents and all turns are aggregated in the "Multi-turn Group Computation" step. This step's output is used to update the "Trained Models" (presumably the Policy Model) while keeping "Frozen Models" (Reference, Reward) unchanged.
* **Training Loop:** The final arrow back to the Policy Model confirms this is an iterative reinforcement learning or optimization process, where group-based reward signals are used to refine the policy.
### Key Observations
1. **Variable-Length Sequences:** The system explicitly handles sequences of different lengths (`t₃`, `t_G`), which is crucial for realistic multi-turn interactions.
2. **Granular Reward Signal:** Rewards are provided at the action-level, not just at the end of a sequence. This allows for fine-grained credit assignment across multiple turns.
3. **Model State Dichotomy:** The diagram strictly separates "Trained" (Policy) and "Frozen" (Reference, Reward) components, which is a common practice in stable reinforcement learning algorithms like RLHF.
4. **Group-Based Learning:** The title "Group Computation" and the indexing by `G` suggest the algorithm processes multiple rollouts (from different agents or attempts) simultaneously to compute a more robust training signal.
### Interpretation
This diagram outlines the **Flow-GRPO** (likely "Flow-based Group Relative Policy Optimization") algorithm, a method for training agentic AI systems that operate over multiple turns. The core innovation appears to be the integration of **group-based computation** with **multi-turn, action-level rewards**.
* **Purpose:** To train a policy model (`Policy Model`) to perform well in sequential decision-making tasks by comparing the relative performance of multiple rollouts (a "group") generated under the same conditions.
* **Mechanism:** The KL divergence constraint between the Policy and Reference models prevents the policy from deviating too drastically during updates, ensuring stability. The Reward Model provides dense feedback. The "Group Computation" likely calculates advantages or normalized rewards across the group of rollouts, which are then used to update the policy via a gradient step (indicated by the return arrow).
* **Significance:** This approach addresses key challenges in training multi-turn agents: credit assignment over long horizons and obtaining stable, comparative learning signals. By evaluating groups of trajectories together, it can mitigate noise and learn more robustly than methods relying on single rollouts. The architecture is modular, allowing different frozen models (Reference, Reward) to be plugged in.