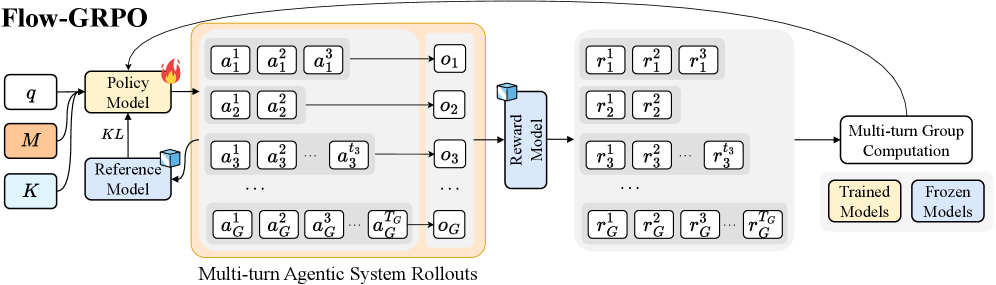
## Flowchart: Flow-GRPO Architecture
### Overview
The diagram illustrates a multi-stage reinforcement learning framework called Flow-GRPO, depicting the flow of information between policy models, reference models, reward models, and group computation systems. The architecture emphasizes iterative agent-environment interactions and model-based reward aggregation.
### Components/Axes
1. **Input Components** (Left):
- `q`: Query/input state
- `M`: Policy Model parameters
- `K`: Reference Model parameters
- Color coding: Orange (`M`), Blue (`K`)
2. **Core Components**:
- **Policy Model**:
- Inputs: `q`, `M`, `K`
- Outputs: Action sequence `a₁¹, a₁², ..., a₁ᴺ` (per turn)
- **Reference Model**:
- Connected via KL divergence to Policy Model
- **Multi-turn Agentic System Rollouts**:
- Action sequences: `a₁¹, a₂¹, ..., aᴺ¹` (turn 1), `a₁², a₂², ..., aᴺ²` (turn 2), ..., `a₁ᴺ, a₂ᴺ, ..., aᴺᴺ` (turn N)
- Observation sequence: `o₁, o₂, ..., oᴺ`
- **Reward Model**:
- Inputs: Action-observation pairs
- Outputs: Reward sequence `r₁¹, r₁², ..., r₁ᴺ` (per agent)
- **Multi-turn Group Computation**:
- Inputs: Trained Models (`r₁¹, r₂¹, ..., rᴺ¹`) and Frozen Models (`r₁ᴺ, r₂ᴺ, ..., rᴺᴺ`)
- Output: Aggregated group rewards
3. **Legend**:
- Yellow: Trained Models
- Blue: Frozen Models
### Detailed Analysis
- **Policy Model**: Generates action sequences (`aᴺᴺ`) through iterative turns, with each turn's actions (`aᴺᴺ`) influencing subsequent observations (`oᴺ`).
- **Reference Model**: Acts as a knowledge distillation component, connected to the Policy Model via KL divergence (indicated by the flame icon).
- **Multi-turn Rollouts**: Show temporal progression through action-observation pairs, with subscript indices denoting turn number and superscript indices denoting agent/episode.
- **Reward Model**: Processes rollout data to compute per-agent rewards (`rᴺᴺ`), with separate tracks for trained and frozen model outputs.
- **Group Computation**: Combines trained (`rᴺ¹`) and frozen (`rᴺᴺ`) model rewards through an unspecified aggregation mechanism.
### Key Observations
1. **Temporal Structure**: The system processes N discrete turns, with each turn's actions (`aᴺᴺ`) and observations (`oᴺ`) forming a Markovian chain.
2. **Model Diversity**: Maintains separate trained and frozen model tracks, suggesting ensemble learning or robustness testing.
3. **Reward Aggregation**: Final computation combines multiple reward streams, implying a meta-learning or distillation objective.
4. **Knowledge Distillation**: The KL divergence connection between Policy and Reference Models indicates parameter sharing or guidance mechanisms.
### Interpretation
This architecture represents a sophisticated RL framework where:
1. **Policy Development**: The Policy Model evolves through iterative interactions with the environment, guided by a Reference Model.
2. **Reward Engineering**: The Reward Model extracts value signals from raw interactions, with separate evaluation paths for different model versions.
3. **Ensemble Learning**: The final group computation likely combines diverse model perspectives, potentially for uncertainty reduction or performance improvement.
The diagram suggests a research direction focused on improving RL stability through:
- Model diversity (trained vs frozen)
- Temporal credit assignment across multiple turns
- Knowledge distillation between models
- Group-level reward aggregation for collective decision-making