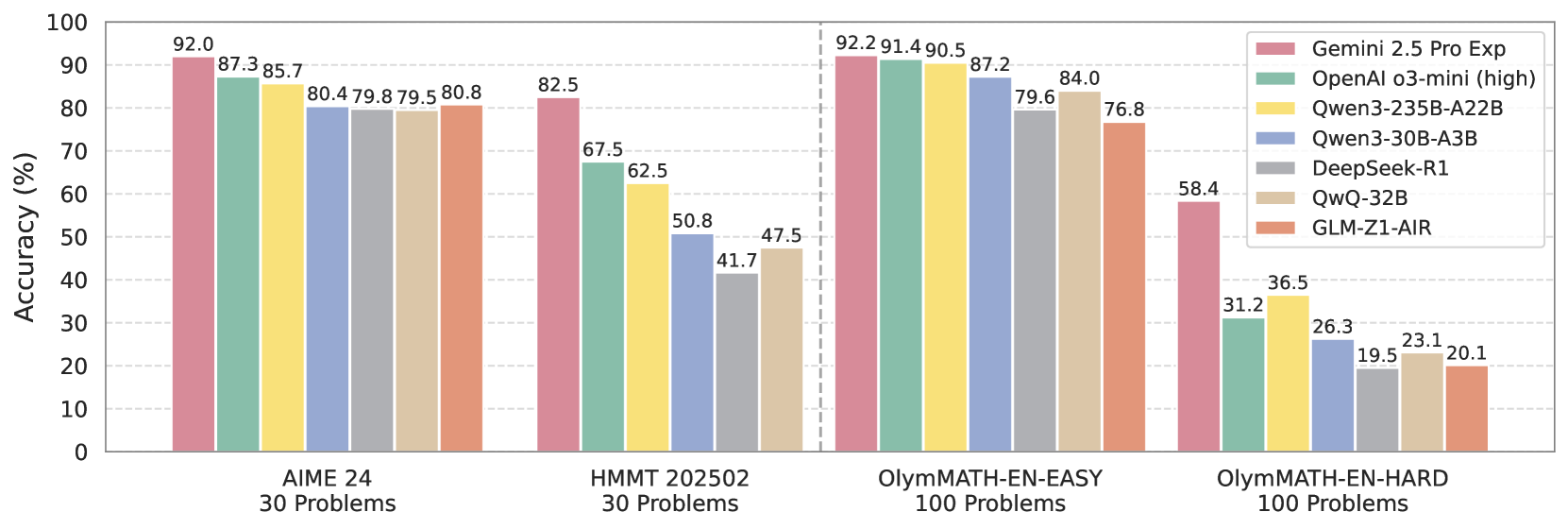
## Grouped Bar Chart: AI Model Accuracy on Mathematical Problem Sets
### Overview
The image is a grouped bar chart comparing the accuracy percentages of seven different AI models across four distinct mathematical problem sets. The chart is designed to benchmark model performance on increasingly difficult math competitions and problem collections.
### Components/Axes
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 0 to 100 in increments of 10.
* **X-Axis:** Represents four different problem sets, grouped as follows:
1. **AIME 24** (30 Problems)
2. **HMMT 202502** (30 Problems)
3. **OlymMATH-EN-EASY** (100 Problems)
4. **OlymMATH-EN-HARD** (100 Problems)
* **Legend:** Located in the top-right corner. It maps colors to seven AI models:
* Pinkish-Red: **Gemini 2.5 Pro Exp**
* Teal Green: **OpenAI o3-mini (high)**
* Yellow: **Qwen3-235B-A22B**
* Light Blue: **Qwen3-30B-A3B**
* Grey: **DeepSeek-R1**
* Beige: **QwQ-32B**
* Salmon/Orange: **GLM-Z1-AIR**
### Detailed Analysis
**1. AIME 24 (30 Problems)**
* **Trend:** All models perform relatively well, with scores clustered between ~80% and 92%.
* **Data Points (from left to right bar in the group):**
* Gemini 2.5 Pro Exp: **92.0%**
* OpenAI o3-mini (high): **87.3%**
* Qwen3-235B-A22B: **85.7%**
* Qwen3-30B-A3B: **80.4%**
* DeepSeek-R1: **79.8%**
* QwQ-32B: **79.5%**
* GLM-Z1-AIR: **80.8%**
**2. HMMT 202502 (30 Problems)**
* **Trend:** A significant performance drop for all models compared to AIME 24. The spread between models widens considerably.
* **Data Points:**
* Gemini 2.5 Pro Exp: **82.5%**
* OpenAI o3-mini (high): **67.5%**
* Qwen3-235B-A22B: **62.5%**
* Qwen3-30B-A3B: **50.8%**
* DeepSeek-R1: **41.7%**
* QwQ-32B: **47.5%**
* GLM-Z1-AIR: **47.5%** (Note: The bar for GLM-Z1-AIR appears to be the same height as QwQ-32B, but the label is missing. Based on visual alignment, it is approximately 47.5%.)
**3. OlymMATH-EN-EASY (100 Problems)**
* **Trend:** Performance rebounds for most models, with scores again clustered in a high range (76%-92%), similar to the AIME 24 benchmark.
* **Data Points:**
* Gemini 2.5 Pro Exp: **92.2%**
* OpenAI o3-mini (high): **91.4%**
* Qwen3-235B-A22B: **90.5%**
* Qwen3-30B-A3B: **87.2%**
* DeepSeek-R1: **79.6%**
* QwQ-32B: **84.0%**
* GLM-Z1-AIR: **76.8%**
**4. OlymMATH-EN-HARD (100 Problems)**
* **Trend:** A dramatic and universal performance collapse. All models score below 60%, with most below 40%. This indicates a substantial increase in problem difficulty.
* **Data Points:**
* Gemini 2.5 Pro Exp: **58.4%**
* OpenAI o3-mini (high): **31.2%**
* Qwen3-235B-A22B: **36.5%**
* Qwen3-30B-A3B: **26.3%**
* DeepSeek-R1: **19.5%**
* QwQ-32B: **23.1%**
* GLM-Z1-AIR: **20.1%**
### Key Observations
1. **Consistent Leader:** Gemini 2.5 Pro Exp (pinkish-red bar) is the top-performing model on every single benchmark.
2. **Difficulty Cliff:** There is a stark performance cliff between the "EASY" and "HARD" OlymMATH sets. The highest score drops from 92.2% to 58.4%, and the lowest from 76.8% to 19.5%.
3. **Model Hierarchy Shift:** While the general order of model performance is somewhat preserved across benchmarks, there are notable shifts. For example, Qwen3-235B-A22B (yellow) is often the second or third best, but on the hardest set (OlymMATH-EN-HARD), it outperforms OpenAI o3-mini (high).
4. **Performance Clustering:** On the easier tasks (AIME 24, OlymMATH-EN-EASY), models form a tight cluster. On harder tasks (HMMT 202502, OlymMATH-EN-HARD), the performance gap between the top model and the rest widens significantly.
### Interpretation
This chart provides a comparative snapshot of AI reasoning capabilities in mathematics. The data suggests several key insights:
* **Benchmark Sensitivity:** Model performance is highly sensitive to the specific benchmark. Success on one type of math competition (AIME) does not guarantee similar success on another (HMMT), even when problem counts are equal.
* **The "Hard Problem" Barrier:** The catastrophic drop in scores on OlymMATH-EN-HARD reveals a current frontier in AI mathematical reasoning. The problems in this set likely require deeper abstraction, multi-step logical chains, or creative problem-solving approaches that current models struggle with, despite excelling at more standardized competition problems.
* **Model Robustness:** Gemini 2.5 Pro Exp demonstrates the most robust performance, maintaining a significant lead even as difficulty spikes. This could indicate superior generalization or a more advanced underlying reasoning architecture.
* **Practical Implications:** For users or developers selecting a model for mathematical tasks, the choice depends heavily on the expected problem difficulty. For "easier" competition-level math, several models are highly capable. For research-level or exceptionally hard problems, the field has a significant gap to close, with one model currently leading the pack.
**Language Note:** All text in the image is in English.