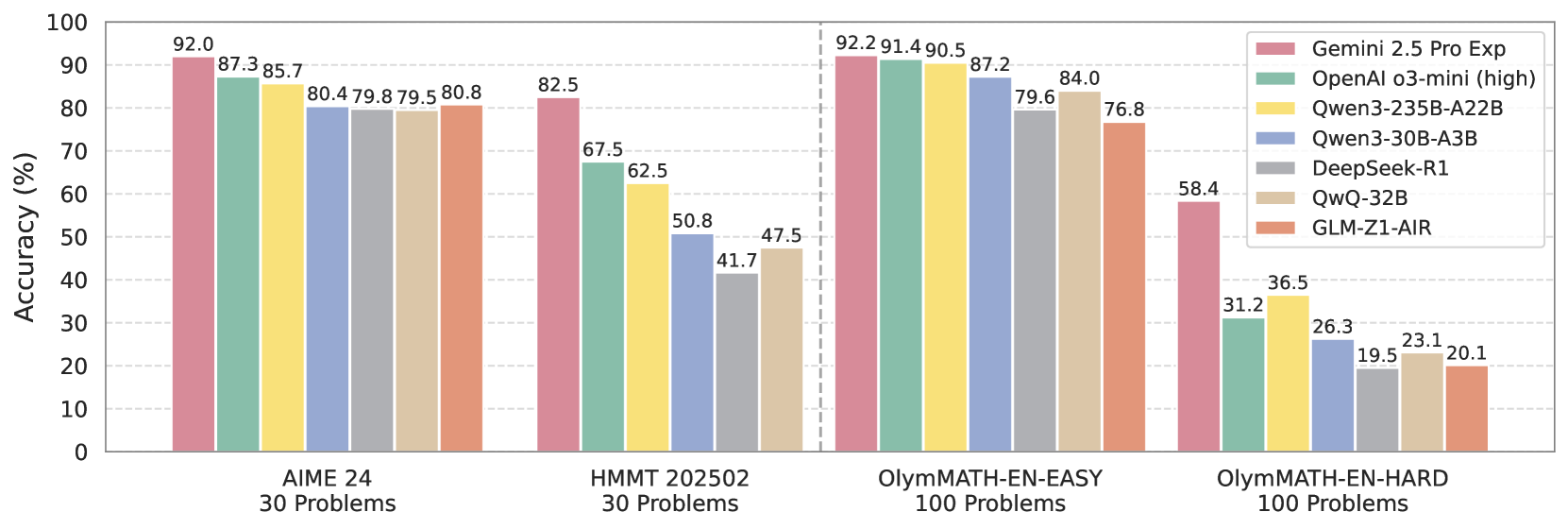
# Technical Document Extraction: AI Model Accuracy Comparison
## Chart Type
Bar chart comparing AI model accuracy across four mathematical problem datasets.
## Axes Labels
- **Y-axis**: Accuracy (%) [0-100 scale]
- **X-axis**: Datasets
- AIME 24 (30 Problems)
- HMMT 202502 (30 Problems)
- OlympMATH-EN-EASY (100 Problems)
- OlympMATH-EN-HARD (100 Problems)
## Legend
Right-aligned legend with 7 color-coded models:
1. 🟣 Gemini 2.5 Pro Exp
2. 🟩 OpenAI o3-mini (high)
3. 🟨 Qwen3-235B-A22B
4. 🟦 Qwen3-30B-A3B
5. 🟫 DeepSeek-R1
6. 🟫 QwQ-32B
7. 🟥 GLM-Z1-AIR
## Spatial Grounding
- Legend position: [x=100%, y=0-100%] (right edge)
- Dataset labels positioned at bottom center of each bar group
- Accuracy values displayed above each bar
## Data Points (Accuracy %)
### AIME 24 (30 Problems)
| Model | Accuracy |
|----------------------|----------|
| Gemini 2.5 Pro Exp | 92.0 |
| OpenAI o3-mini | 87.3 |
| Qwen3-235B-A22B | 85.7 |
| Qwen3-30B-A3B | 80.4 |
| DeepSeek-R1 | 79.8 |
| QwQ-32B | 79.5 |
| GLM-Z1-AIR | 80.8 |
### HMMT 202502 (30 Problems)
| Model | Accuracy |
|----------------------|----------|
| Gemini 2.5 Pro Exp | 82.5 |
| OpenAI o3-mini | 67.5 |
| Qwen3-235B-A22B | 62.5 |
| Qwen3-30B-A3B | 50.8 |
| DeepSeek-R1 | 41.7 |
| QwQ-32B | 47.5 |
| GLM-Z1-AIR | - |
### OlympMATH-EN-EASY (100 Problems)
| Model | Accuracy |
|----------------------|----------|
| Gemini 2.5 Pro Exp | 92.2 |
| OpenAI o3-mini | 91.4 |
| Qwen3-235B-A22B | 90.5 |
| Qwen3-30B-A3B | 87.2 |
| DeepSeek-R1 | 79.6 |
| QwQ-32B | 84.0 |
| GLM-Z1-AIR | 76.8 |
### OlympMATH-EN-HARD (100 Problems)
| Model | Accuracy |
|----------------------|----------|
| Gemini 2.5 Pro Exp | 58.4 |
| OpenAI o3-mini | 31.2 |
| Qwen3-235B-A22B | 36.5 |
| Qwen3-30B-A3B | 26.3 |
| DeepSeek-R1 | 19.5 |
| QwQ-32B | 23.1 |
| GLM-Z1-AIR | 20.1 |
## Key Trends
1. **Dataset Difficulty Gradient**:
- AIME 24 (easiest): Highest accuracies (79.5-92.0%)
- OlympMATH-EN-HARD (hardest): Lowest accuracies (19.5-58.4%)
2. **Model Performance Patterns**:
- Gemini 2.5 Pro Exp maintains top performance across all datasets
- OpenAI o3-mini shows strongest performance in OlympMATH-EN-EASY
- QwQ-32B demonstrates consistent mid-range performance
- DeepSeek-R1 shows significant performance drop in OlympMATH-EN-HARD
3. **Accuracy Degradation**:
- Average accuracy drop from AIME 24 to OlympMATH-EN-HARD:
- Gemini 2.5 Pro Exp: -33.6%
- OpenAI o3-mini: -56.1%
- Qwen3-235B-A22B: -49.2%
## Color Verification
All bar colors match legend specifications:
- 🟣 = Gemini 2.5 Pro Exp (magenta)
- 🟩 = OpenAI o3-mini (green)
- 🟨 = Qwen3-235B-A22B (yellow)
- 🟦 = Qwen3-30B-A3B (blue)
- 🟫 = DeepSeek-R1 (gray)
- 🟫 = QwQ-32B (brown)
- 🟥 = GLM-Z1-AIR (red)
## Data Table Reconstruction
| Dataset | Gemini 2.5 Pro Exp | OpenAI o3-mini | Qwen3-235B-A22B | Qwen3-30B-A3B | DeepSeek-R1 | QwQ-32B | GLM-Z1-AIR |
|-----------------------|--------------------|----------------|-----------------|---------------|-------------|---------|------------|
| AIME 24 (30) | 92.0 | 87.3 | 85.7 | 80.4 | 79.8 | 79.5 | 80.8 |
| HMMT 202502 (30) | 82.5 | 67.5 | 62.5 | 50.8 | 41.7 | 47.5 | - |
| OlympMATH-EN-EASY (100)| 92.2 | 91.4 | 90.5 | 87.2 | 79.6 | 84.0 | 76.8 |
| OlympMATH-EN-HARD (100)| 58.4 | 31.2 | 36.5 | 26.3 | 19.5 | 23.1 | 20.1 |
## Language Analysis
- All text in English
- No non-English content detected