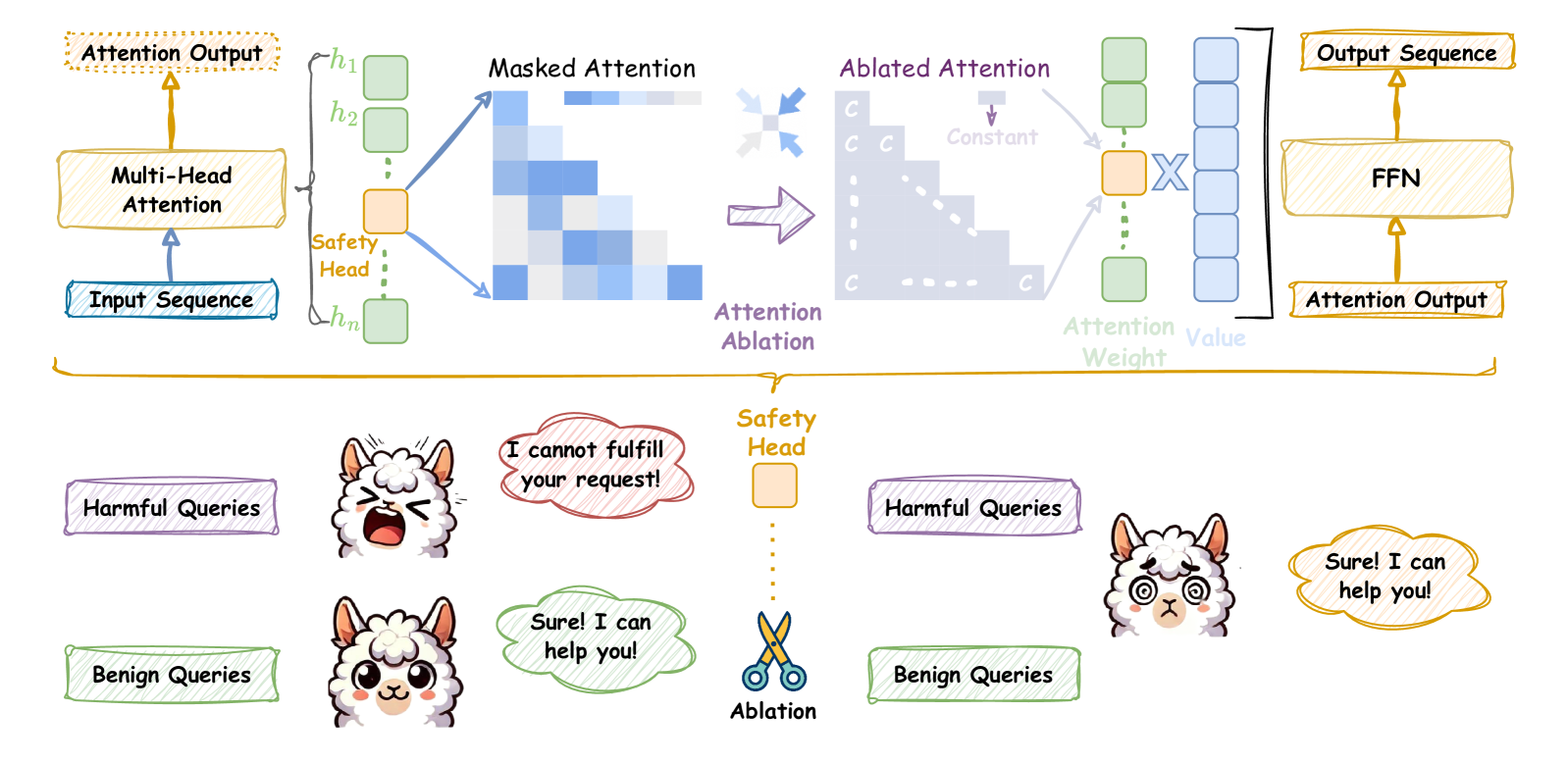
## Diagram: Safety Head Ablation
### Overview
The image illustrates the concept of "Safety Head Ablation" in a neural network, likely within a transformer architecture. It shows how ablating (removing) a specific "Safety Head" affects the model's behavior, particularly in handling harmful versus benign queries. The diagram contrasts the model's response with and without the Safety Head.
### Components/Axes
* **Top Section:** Depicts the neural network architecture.
* **Input Sequence:** The initial input to the model (bottom-left).
* **Multi-Head Attention:** A standard attention mechanism, processing the input sequence.
* **Attention Output:** The output of the multi-head attention layer.
* **h1, h2, ..., hn:** Represent individual attention heads, with the "Safety Head" highlighted in orange.
* **Masked Attention:** Visualizes the attention pattern with masking.
* **Ablated Attention:** Shows the attention pattern after ablating the Safety Head, where the attention weights are set to a constant value 'C'.
* **Attention Ablation:** Label indicating the transition from Masked Attention to Ablated Attention.
* **Attention Weight:** Indicates the weights assigned to the values.
* **Value:** Represents the values being attended to.
* **Output Sequence:** The final output of the attention mechanism.
* **FFN:** Feed-Forward Network, processing the output sequence.
* **Attention Output:** The final output of the FFN.
* **Bottom Section:** Illustrates the model's responses to harmful and benign queries with and without the Safety Head.
* **Harmful Queries:** Labeled input representing potentially harmful prompts.
* **Benign Queries:** Labeled input representing safe prompts.
* **Safety Head:** Represented as an orange box, with dotted lines indicating its ablation.
* **Ablation:** Represented by a pair of scissors, symbolizing the removal of the Safety Head.
* **Speech Bubbles:** Contain the model's responses to the queries.
### Detailed Analysis or ### Content Details
* **Neural Network Architecture (Top Section):**
* The input sequence flows into a multi-head attention mechanism.
* The multi-head attention consists of multiple attention heads (h1 to hn), one of which is designated as the "Safety Head".
* The "Safety Head" is connected to a "Masked Attention" visualization, showing a triangular attention pattern.
* "Attention Ablation" is performed, resulting in "Ablated Attention" where the attention weights from the Safety Head are replaced with a constant value 'C'.
* The ablated attention is then used to compute the "Attention Weight" and "Value", leading to the "Output Sequence" and final "Attention Output" via an FFN.
* **Query Response (Bottom Section):**
* **Before Ablation:**
* A "Harmful Query" results in the model saying "I cannot fulfill your request!".
* A "Benign Query" results in the model saying "Sure! I can help you!".
* **After Ablation:**
* A "Harmful Query" now results in the model saying "Sure! I can help you!".
* A "Benign Query" still results in the model saying "Sure! I can help you!".
### Key Observations
* The Safety Head appears to be responsible for detecting and blocking harmful queries.
* Ablating the Safety Head causes the model to respond positively to both harmful and benign queries.
* The "Masked Attention" visualization shows a pattern where the model attends to previous tokens in the sequence.
* The "Ablated Attention" visualization shows a uniform attention pattern after ablation.
### Interpretation
The diagram demonstrates the importance of the Safety Head in preventing the model from responding to harmful queries. By ablating the Safety Head, the model loses its ability to distinguish between harmful and benign inputs, leading to potentially undesirable behavior. This highlights the role of specific attention heads in controlling the model's safety and ethical considerations. The ablation study suggests that targeted interventions, such as removing specific attention heads, can significantly impact the model's overall behavior and safety profile.