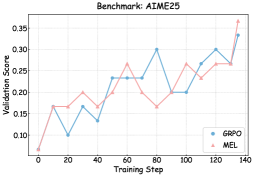
## Chart: Validation Score vs. Training Step for AIME25 Benchmark
### Overview
The image is a line chart comparing the validation scores of two models, GRPO and MEL, over training steps for the AIME25 benchmark. The x-axis represents the training step, and the y-axis represents the validation score.
### Components/Axes
* **Title:** Benchmark: AIME25
* **X-axis:** Training Step, ranging from 0 to 140 in increments of 20.
* **Y-axis:** Validation Score, ranging from 0.10 to 0.35 in increments of 0.05.
* **Legend:** Located in the bottom-right corner.
* GRPO (Blue)
* MEL (Pink)
### Detailed Analysis
* **GRPO (Blue):**
* Starts at approximately 0.07 at step 0.
* Decreases to approximately 0.10 at step 20.
* Increases to approximately 0.17 at step 40.
* Increases to approximately 0.23 at step 60.
* Remains at approximately 0.23 at step 80.
* Decreases to approximately 0.20 at step 100.
* Increases to approximately 0.27 at step 120.
* Increases to approximately 0.33 at step 140.
* **MEL (Pink):**
* Starts at approximately 0.07 at step 0.
* Increases to approximately 0.17 at step 20.
* Increases to approximately 0.17 at step 40.
* Increases to approximately 0.23 at step 60.
* Decreases to approximately 0.17 at step 80.
* Increases to approximately 0.27 at step 100.
* Decreases to approximately 0.23 at step 120.
* Increases to approximately 0.36 at step 140.
### Key Observations
* Both models start with a similar validation score.
* GRPO shows a more consistent upward trend towards the end of the training steps.
* MEL fluctuates more, with a notable peak at the end.
### Interpretation
The chart compares the performance of two models, GRPO and MEL, on the AIME25 benchmark. The validation scores indicate how well each model generalizes to unseen data during training. GRPO appears to have a more stable and consistent improvement in validation score as training progresses, while MEL shows more fluctuation but ultimately reaches a higher validation score at the end of the training steps. This suggests that MEL might be overfitting to the training data or that it requires further regularization. GRPO, on the other hand, might be more robust and generalize better.