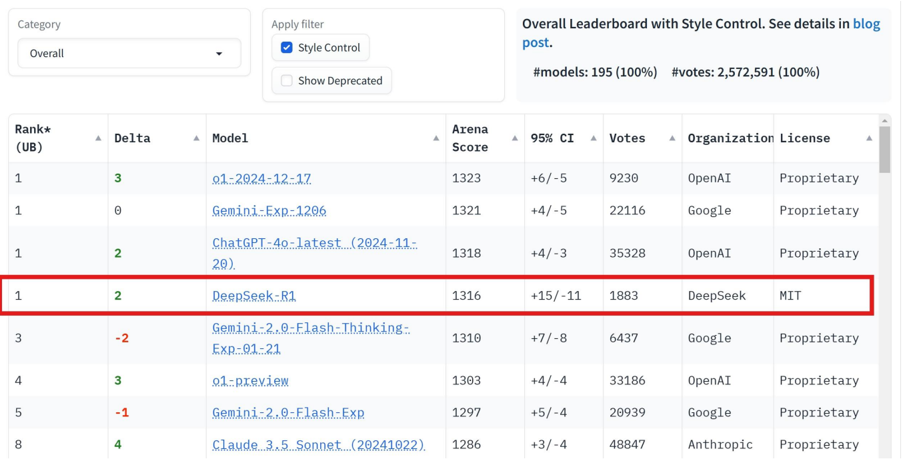
## Data Table: Overall Leaderboard with Style Control
### Overview
This image presents a data table displaying a leaderboard of models, likely large language models (LLMs), ranked based on their performance as measured by the Arena Score. The table includes additional metrics such as Delta (change in rank), votes received, and the organization license under which the model is released. The leaderboard is filtered to show models with "Style Control" enabled.
### Components/Axes
* **Category:** "Overall" is selected. A filter option is available to apply filters.
* **Rank (UB):** Numerical ranking of the models, with ties indicated by the same rank number.
* **Delta:** Change in rank compared to a previous evaluation.
* **Model:** Name of the model.
* **Arena Score:** A numerical score representing the model's performance.
* **95% CI:** 95% Confidence Interval for the Arena Score.
* **Votes:** Number of votes received by the model.
* **Organization License:** The licensing terms under which the model is released.
* **Filters:** "Style Control" is checked. "Show Deprecated" is unchecked.
* **Overall Leaderboard Information:** "#models: 195 (100%)", "votes: 2,572,591 (100%)"
### Detailed Analysis or Content Details
The table contains the following data points (approximate values):
| Rank (UB) | Delta | Model | Arena Score | 95% CI | Votes | Organization License |
| :-------- | :---- | :-------------------------- | :---------- | :----- | :---- | :------------------- |
| 1 | 3 | ot-2024-12-17 | 1323 | +6/-5 | 9230 | OpenAI |
| 1 | 0 | Gemini-1.0-Pro | 1321 | +4/-5 | 22116 | Google |
| 1 | 2 | ChatGPT-4o-latest (2024-11-29) | 1318 | +4/-3 | 35328 | OpenAI |
| 1 | 2 | DeepSeek-R1 | 1316 | +15/-11| 1883 | DeepSeek |
| 3 | -2 | Gemini-1.0-Flash-Thinking-Exp-01-21 | 1310 | +7/-8 | 6437 | Google |
| 4 | 3 | ot-preview | 1303 | +4/-4 | 33186 | OpenAI |
| 5 | -1 | Gemini-1.0-Flash-Exp | 1297 | +5/-4 | 20939 | Google |
| 8 | 4 | Claude-3.5-Sonnet (20240222) | 1286 | +3/-4 | 48847 | Anthropic |
**Trends:**
* The top three models (ot-2024-12-17, Gemini-1.0-Pro, and ChatGPT-4o-latest) are closely ranked with Arena Scores around 1320.
* DeepSeek-R1 is also highly ranked, tied for first place.
* Gemini models appear multiple times in the top rankings.
* The Delta values indicate some models have improved their ranking (positive Delta), while others have declined (negative Delta).
### Key Observations
* There are ties in the ranking, with multiple models sharing the same rank (e.g., three models are tied for 1st place).
* The 95% Confidence Intervals (CI) vary, indicating different levels of certainty in the Arena Score estimates. DeepSeek-R1 has a relatively wide CI (+15/-11), suggesting more uncertainty in its score.
* ChatGPT-4o-latest has the highest number of votes (35328), indicating it has been evaluated by a large number of users.
* The models are released under different licenses, with OpenAI and Google primarily using "Proprietary" licenses, while DeepSeek uses the MIT license.
### Interpretation
The data suggests a competitive landscape among LLMs, with several models performing at a high level. The Arena Score provides a quantitative measure of model performance, while the votes indicate user engagement and preference. The Delta values highlight the dynamic nature of the leaderboard, as models are continuously updated and improved. The presence of multiple models from Google and OpenAI suggests these organizations are leading the development of LLMs. The varying confidence intervals indicate that some models have more stable and reliable performance estimates than others. The licensing information is important for understanding the terms of use and potential commercial applications of each model. The high number of votes for ChatGPT-4o-latest suggests it is a popular and widely used model. The leaderboard provides valuable insights for researchers, developers, and users interested in comparing and selecting LLMs for specific tasks.