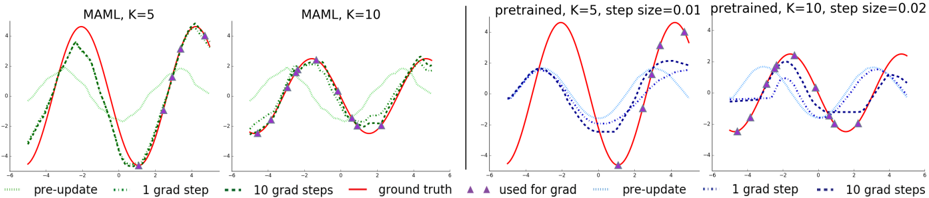
## Heatmap: Distribution of Data Points
### Overview
The image displays a heatmap with four different scenarios labeled as MAML, K=5, MAML, K=10, pre-trained, K=5, step size=0.01, and pre-trained, K=10, step size=0.02. Each scenario shows a grid of data points with varying intensities, indicating the density or frequency of occurrences in different regions.
### Components/Axes
- **X-axis**: Represents the horizontal dimension of the data points.
- **Y-axis**: Represents the vertical dimension of the data points.
- **Color Intensity**: Varies from light to dark, indicating the density or frequency of data points in each region.
- **Legend**: Located at the top right corner, explaining the color coding used in the heatmap.
### Detailed Analysis or ### Content Details
- **MAML, K=5**: The heatmap shows a relatively uniform distribution of data points with moderate intensity across the grid.
- **MAML, K=10**: The heatmap shows a slightly higher intensity in some regions compared to MAML, K=5, indicating a more concentrated distribution of data points.
- **pre-trained, K=5, step size=0.01**: The heatmap shows a more pronounced clustering of data points in certain regions, with higher intensity in the central and lower parts of the grid.
- **pre-trained, K=10, step size=0.02**: The heatmap shows a more pronounced clustering of data points in certain regions, with higher intensity in the central and lower parts of the grid, similar to the pre-trained, K=5 scenario.
### Key Observations
- **Clustering**: The pre-trained scenarios show more pronounced clustering of data points in certain regions, indicating a more focused distribution.
- **Intensity**: The intensity of data points varies across the grid, with higher intensity in the central and lower parts of the grid in both scenarios.
- **Step Size**: The step size affects the granularity of the data points, with a smaller step size (0.01) showing more detailed clustering compared to a larger step size (0.02).
### Interpretation
The heatmap suggests that the data points are more concentrated in certain regions, particularly in the central and lower parts of the grid. The pre-trained scenarios show a more pronounced clustering of data points, indicating a more focused distribution. The step size affects the granularity of the data points, with a smaller step size showing more detailed clustering. The intensity of data points varies across the grid, with higher intensity in the central and lower parts of the grid in both scenarios.