\n
## Bar Chart: BioLP-Bench Performance
### Overview
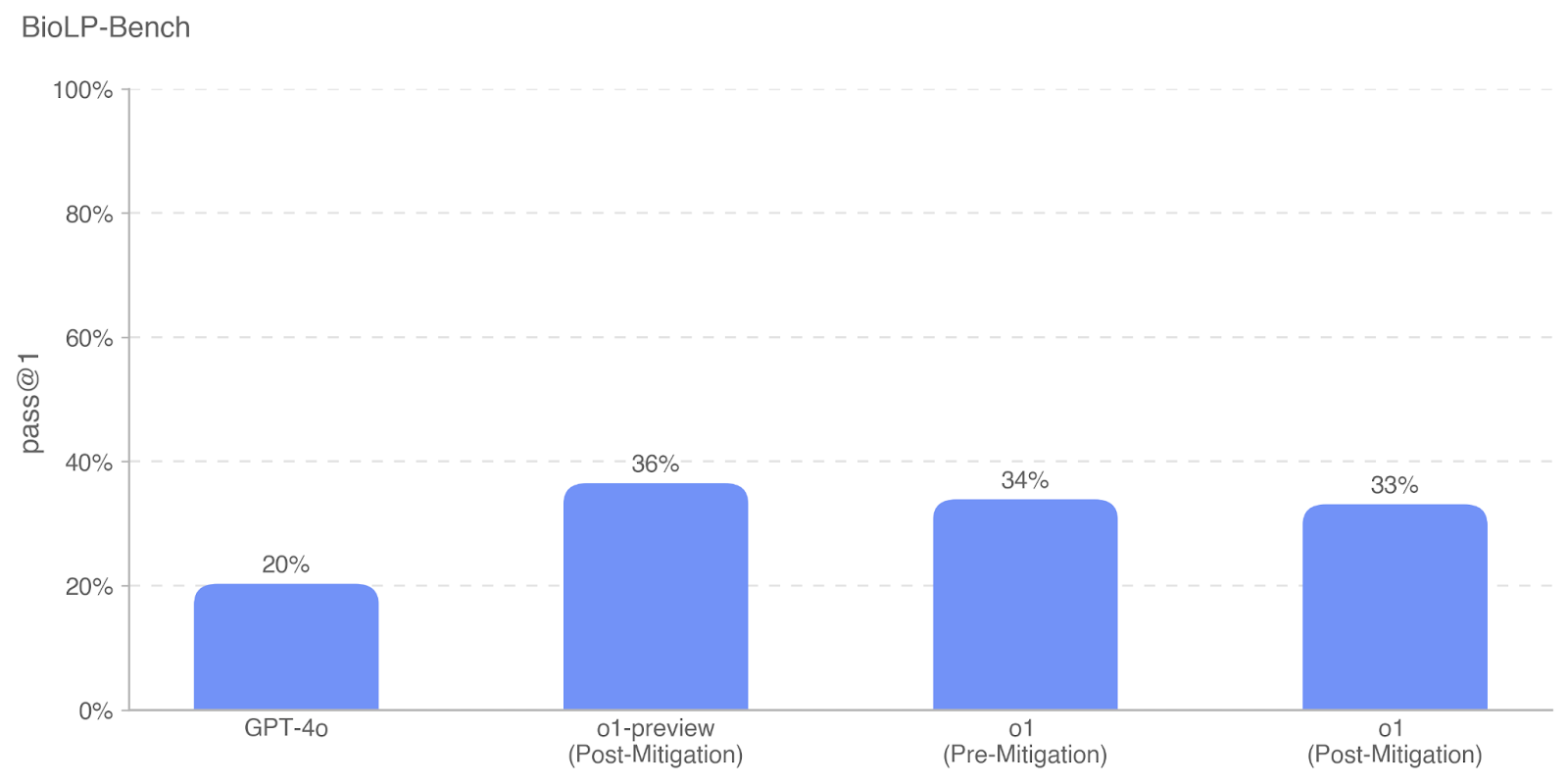
The image presents a bar chart comparing the "pass @ 1" performance of different models on the BioLP-Bench benchmark. The models compared are GPT-4o, o1-preview (Post-Mitigation), o1 (Pre-Mitigation), and o1 (Post-Mitigation). The chart visually represents the percentage of times each model passes the benchmark on the first attempt.
### Components/Axes
* **Title:** BioLP-Bench (positioned at the top-left)
* **Y-axis:** "pass @ 1" (labeled on the left side), ranging from 0% to 100% with increments of 20%.
* **X-axis:** Model names (labeled at the bottom): GPT-4o, o1-preview (Post-Mitigation), o1 (Pre-Mitigation), o1 (Post-Mitigation).
* **Bars:** Each bar represents a model, and its height corresponds to the "pass @ 1" percentage. All bars are a light blue color.
### Detailed Analysis
The chart displays the following data points:
* **GPT-4o:** Approximately 20% pass @ 1. The bar reaches the 20% mark on the y-axis.
* **o1-preview (Post-Mitigation):** Approximately 36% pass @ 1. The bar reaches slightly above the 35% mark on the y-axis.
* **o1 (Pre-Mitigation):** Approximately 34% pass @ 1. The bar reaches slightly above the 30% mark on the y-axis.
* **o1 (Post-Mitigation):** Approximately 33% pass @ 1. The bar reaches slightly above the 30% mark on the y-axis.
The bars for "o1-preview (Post-Mitigation)", "o1 (Pre-Mitigation)", and "o1 (Post-Mitigation)" are roughly the same height, indicating similar performance.
### Key Observations
* GPT-4o exhibits the lowest "pass @ 1" performance among the models tested.
* The "o1-preview (Post-Mitigation)" model shows the highest performance, though only marginally better than the other "o1" models.
* The performance of "o1 (Pre-Mitigation)" and "o1 (Post-Mitigation)" is very close.
### Interpretation
The data suggests that the "o1-preview" model, with post-mitigation applied, performs best on the BioLP-Bench benchmark, achieving a 36% pass rate on the first attempt. GPT-4o lags significantly behind, with a 20% pass rate. The comparison between "o1 (Pre-Mitigation)" and "o1 (Post-Mitigation)" indicates that the mitigation strategy applied to the "o1" model has a minimal impact on its performance. The chart highlights the potential benefits of mitigation techniques in improving model performance on this specific benchmark, but also shows that the improvement isn't always substantial. The relatively small differences between the "o1" models suggest that other factors might be influencing performance beyond the mitigation strategy. The large gap between GPT-4o and the other models suggests a fundamental difference in their capabilities or training data related to the BioLP-Bench task.