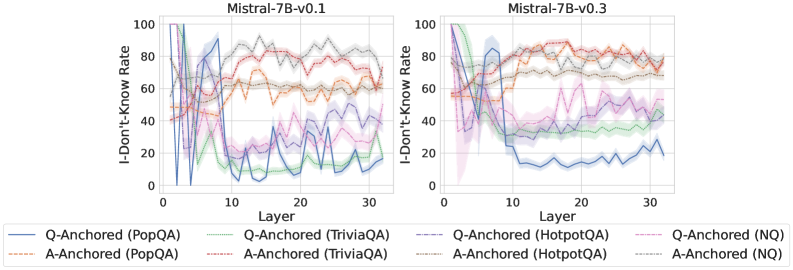
## Line Chart: I-Don't-Know Rate Across Layers for Mistral-7B Models
### Overview
The image contains two side-by-side line charts comparing the "I-Don't-Know Rate" (IDK Rate) across 30 layers for two versions of the Mistral-7B model (v0.1 and v0.3). Each chart includes multiple data series representing different Q-Anchored and A-Anchored models across four datasets: PopQA, TriviaQA, HotpotQA, and NQ. The charts use color-coded lines with solid (Q-Anchored) and dashed (A-Anchored) styles to distinguish between anchoring methods.
### Components/Axes
- **X-axis**: "Layer" (0 to 30), representing the depth of the model's layers.
- **Y-axis**: "I-Don't-Know Rate" (0 to 100), indicating the percentage of instances where the model responded with "I don't know."
- **Legend**:
- **Solid lines**: Q-Anchored models (e.g., Q-Anchored (PopQA), Q-Anchored (TriviaQA), etc.).
- **Dashed lines**: A-Anchored models (e.g., A-Anchored (PopQA), A-Anchored (TriviaQA), etc.).
- **Colors**:
- Blue: Q-Anchored (PopQA)
- Green: Q-Anchored (TriviaQA)
- Orange: Q-Anchored (HotpotQA)
- Red: Q-Anchored (NQ)
- Purple: A-Anchored (PopQA)
- Gray: A-Anchored (TriviaQA)
- Dark gray: A-Anchored (HotpotQA)
- Light gray: A-Anchored (NQ)
### Detailed Analysis
#### Mistral-7B-v0.1
- **Q-Anchored (PopQA)**: Starts at ~90% at layer 0, drops sharply to ~30% by layer 10, then fluctuates between 20-40%.
- **A-Anchored (PopQA)**: Starts at ~50%, remains relatively stable (~40-60%) across layers.
- **Q-Anchored (TriviaQA)**: Peaks at ~80% at layer 0, drops to ~20% by layer 10, then fluctuates between 10-30%.
- **A-Anchored (TriviaQA)**: Starts at ~60%, decreases to ~30% by layer 10, then stabilizes (~20-40%).
- **Q-Anchored (HotpotQA)**: Peaks at ~70% at layer 0, drops to ~20% by layer 10, then fluctuates between 10-30%.
- **A-Anchored (HotpotQA)**: Starts at ~50%, decreases to ~20% by layer 10, then stabilizes (~10-30%).
- **Q-Anchored (NQ)**: Peaks at ~60% at layer 0, drops to ~10% by layer 10, then fluctuates between 5-20%.
- **A-Anchored (NQ)**: Starts at ~40%, decreases to ~10% by layer 10, then stabilizes (~5-15%).
#### Mistral-7B-v0.3
- **Q-Anchored (PopQA)**: Starts at ~70%, drops to ~20% by layer 10, then fluctuates between 10-30%.
- **A-Anchored (PopQA)**: Starts at ~50%, remains stable (~40-60%) across layers.
- **Q-Anchored (TriviaQA)**: Peaks at ~60% at layer 0, drops to ~10% by layer 10, then fluctuates between 5-20%.
- **A-Anchored (TriviaQA)**: Starts at ~50%, decreases to ~20% by layer 10, then stabilizes (~10-30%).
- **Q-Anchored (HotpotQA)**: Peaks at ~60% at layer 0, drops to ~10% by layer 10, then fluctuates between 5-20%.
- **A-Anchored (HotpotQA)**: Starts at ~40%, decreases to ~10% by layer 10, then stabilizes (~5-15%).
- **Q-Anchored (NQ)**: Peaks at ~50% at layer 0, drops to ~5% by layer 10, then fluctuates between 2-10%.
- **A-Anchored (NQ)**: Starts at ~30%, decreases to ~5% by layer 10, then stabilizes (~2-10%).
### Key Observations
1. **Q-Anchored models** (solid lines) exhibit higher variability and sharper declines in IDK rates compared to A-Anchored models (dashed lines).
2. **A-Anchored models** show more stability, with gradual declines or consistent rates across layers.
3. **Dataset-specific trends**:
- **PopQA**: Q-Anchored models start with the highest IDK rates (up to 90% in v0.1) but decline sharply.
- **TriviaQA**: Q-Anchored models have the most dramatic drops (e.g., 80% to 20% in v0.1).
- **NQ**: Q-Anchored models show the steepest declines (e.g., 60% to 10% in v0.1).
4. **Version differences**: Mistral-7B-v0.3 generally has lower baseline IDK rates than v0.1, suggesting improved performance or reduced uncertainty in later layers.
### Interpretation
The data suggests that **Q-Anchored models** (which may prioritize question-specific context) are more sensitive to layer depth, leading to higher initial uncertainty that decreases rapidly. In contrast, **A-Anchored models** (which may rely on broader contextual anchoring) maintain more stable IDK rates, indicating robustness to layer-specific variations. The decline in IDK rates across layers for Q-Anchored models could reflect improved confidence as the model processes deeper layers. However, the variability in trends across datasets highlights that the anchoring method interacts differently with the complexity of each task. The lower baseline rates in v0.3 suggest architectural or training improvements in later versions, though the exact mechanisms remain unclear without additional context.