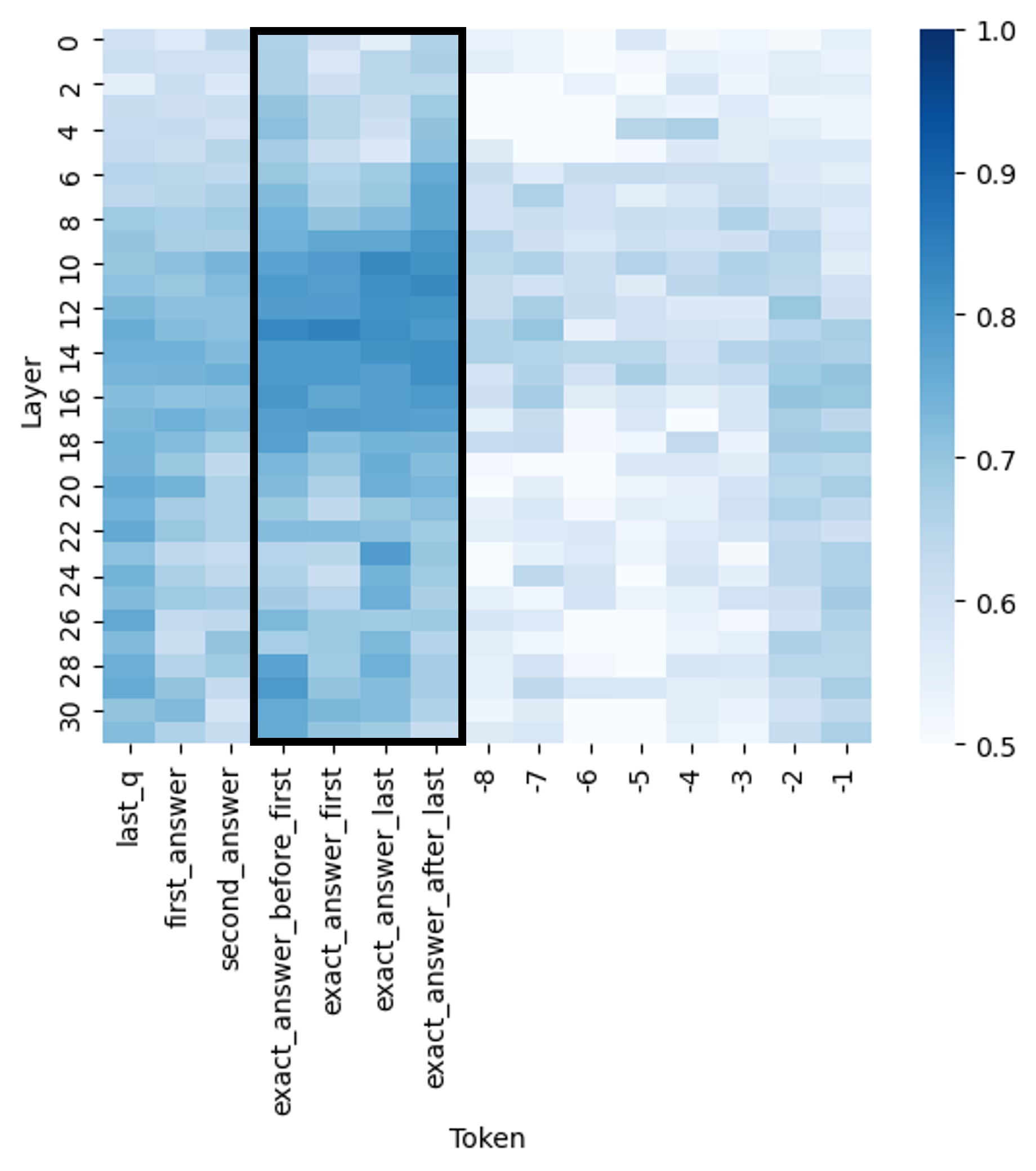
## Heatmap: Attention Weights Across Transformer Layers and Tokens
### Overview
The image is a heatmap visualizing attention weights across 31 transformer layers (0–30) and 11 token categories. Attention values range from 0.5 (light blue) to 1.0 (dark blue), with a highlighted region (black rectangle) emphasizing specific layers and tokens. The heatmap suggests a focus on token relationships and layer-specific processing patterns.
### Components/Axes
- **X-axis (Tokens)**:
`last_q`, `first_answer`, `second_answer`, `exact_answer_before_last`, `exact_answer_last`, `exact_answer_after_last`
(Token categories related to question/answer positions in a sequence)
- **Y-axis (Layers)**:
Layers 0–30 (representing transformer decoder layers in a model)
- **Color Scale**:
Vertical bar on the right, ranging from 0.5 (lightest blue) to 1.0 (darkest blue), indicating attention weight magnitude.
- **Highlighted Region**:
Black rectangle spanning layers 10–20 and tokens `exact_answer_last` to `exact_answer_after_last`.
### Detailed Analysis
- **Token Categories**:
- `last_q`: Appears in all layers, with moderate attention (0.6–0.8).
- `first_answer`, `second_answer`: Lower attention (0.5–0.7) in early layers, increasing slightly in later layers.
- `exact_answer_before_last`, `exact_answer_last`, `exact_answer_after_last`: High attention (0.8–1.0) in layers 10–20, with `exact_answer_last` showing the strongest focus (darkest blue).
- **Layer Trends**:
- Early layers (0–10): Lower overall attention weights (0.5–0.7), with gradual increases toward `exact_answer_last`.
- Middle layers (10–20): Peak attention for `exact_answer_last` and `exact_answer_after_last` (0.9–1.0).
- Later layers (20–30): Attention weights decline slightly (0.7–0.9), with `exact_answer_last` remaining dominant.
- **Color Consistency**:
Darker blues in the highlighted region align with the legend’s 0.9–1.0 range, confirming high attention in this subregion.
### Key Observations
1. **Concentration of Attention**:
The highlighted region (`exact_answer_last`/`exact_answer_after_last` in layers 10–20) shows the highest attention weights, suggesting these tokens are critical for the model’s decision-making.
2. **Layer-Specific Processing**:
Early layers focus on general context (`last_q`), while middle layers specialize in precise answer tokens. Later layers refine these relationships but show reduced intensity.
3. **Uniformity in Later Layers**:
Layers 20–30 exhibit more uniform attention across tokens, possibly indicating stabilized representations.
### Interpretation
This heatmap likely represents attention weights in a transformer-based model (e.g., for question answering). The highlighted region indicates that layers 10–20 prioritize tokens directly related to the exact answer, suggesting these layers are pivotal for extracting precise information. The decline in attention weights in later layers may reflect the model’s consolidation of information rather than active processing. The trend implies that earlier layers handle contextual understanding, while middle layers focus on answer extraction, and later layers refine outputs. The uniformity in later layers could indicate over-smoothing or reduced discriminative power in deeper layers.