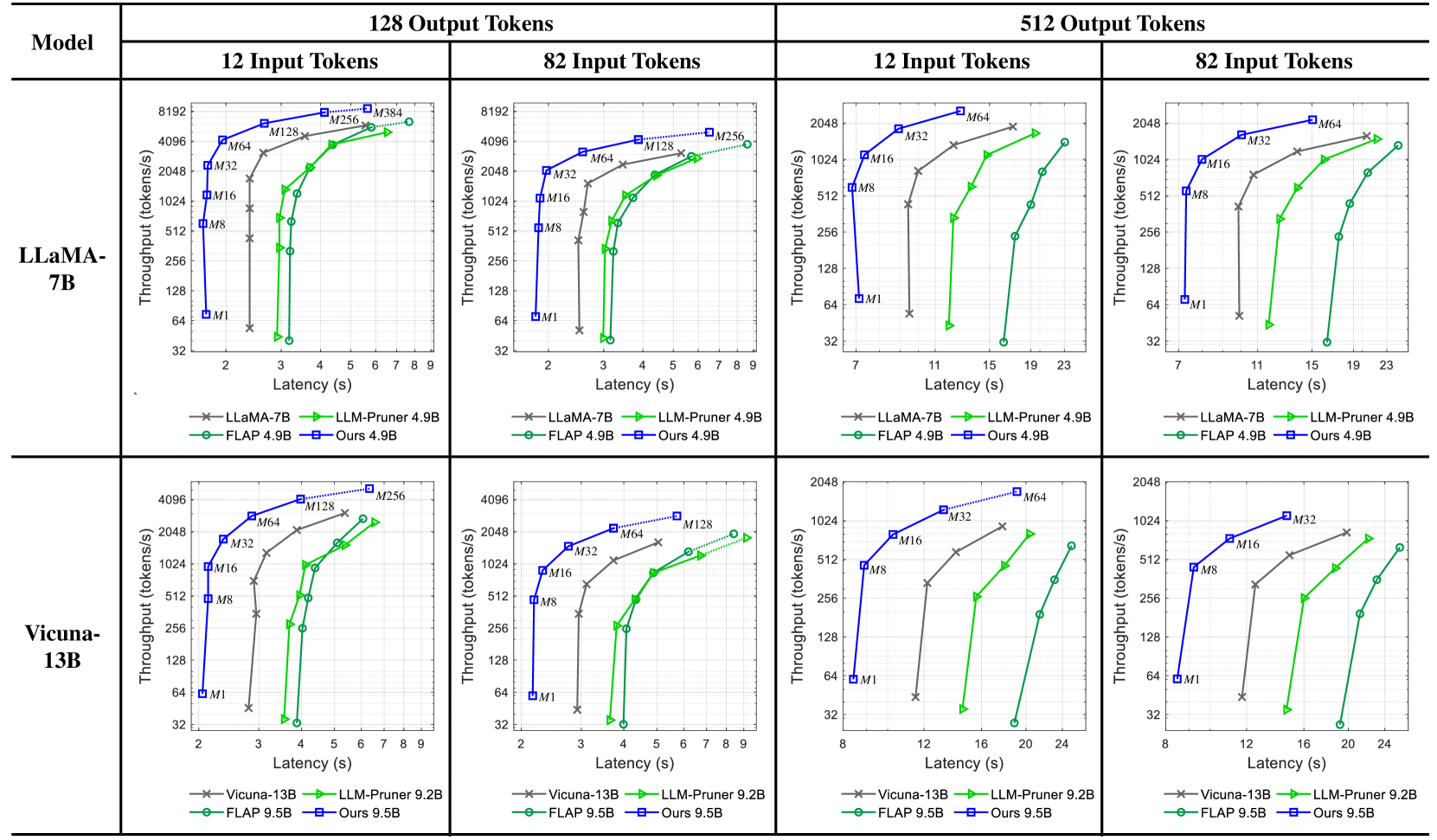
## Line Graphs: Model Performance Comparison Across Token Configurations
### Overview
The image contains eight line graphs comparing the performance of two language models (LLaMA-7B and Vicuna-13B) across four token configuration scenarios (12x128, 82x128, 12x512, 82x512). Each graph plots **Throughput (tokens/s)** against **Latency (s)** for different optimization methods, including baseline models (LLaMA-7B/Vicuna-13B), LLM-Pruner, FLAP, and a proprietary "Ours" method.
---
### Components/Axes
1. **Models**:
- LLaMA-7B (top row)
- Vicuna-13B (bottom row)
2. **Token Configurations**:
- **12 Input Tokens × 128 Output Tokens** (left column)
- **82 Input Tokens × 128 Output Tokens** (middle column)
- **12 Input Tokens × 512 Output Tokens** (right column)
- **82 Input Tokens × 512 Output Tokens** (far-right column)
3. **Methods**:
- **LLaMA-7B/Vicuna-13B** (baseline, gray crosses)
- **LLM-Pruner 4.9B/9.2B** (green triangles)
- **FLAP 4.9B/9.5B** (green circles)
- **Ours 4.9B/9.5B** (blue squares)
**Axes**:
- **X-axis**: Latency (s) ranging from 2–24s (varies slightly by graph)
- **Y-axis**: Throughput (tokens/s) ranging from ~32–8192 tokens/s
---
### Detailed Analysis
#### LLaMA-7B (Top Row)
1. **12x128 Configuration**:
- **LLaMA-7B** (gray): Throughput increases from ~4096 tokens/s at 2s to ~8192 tokens/s at 9s.
- **LLM-Pruner 4.9B** (green): Starts at ~128 tokens/s (2s) and reaches ~4096 tokens/s (9s).
- **FLAP 4.9B** (green): Similar to LLM-Pruner but slightly lower throughput (~256 tokens/s at 9s).
- **Ours 4.9B** (blue): Outperforms all, reaching ~8192 tokens/s at 9s.
2. **82x128 Configuration**:
- **LLaMA-7B**: Throughput rises from ~128 tokens/s (2s) to ~4096 tokens/s (9s).
- **Ours 4.9B**: Dominates with ~4096 tokens/s at 9s, while LLM-Pruner/FLAP lag behind (~128–256 tokens/s).
3. **12x512 Configuration**:
- **LLaMA-7B**: Throughput increases from ~256 tokens/s (7s) to ~4096 tokens/s (23s).
- **Ours 4.9B**: Reaches ~4096 tokens/s at 15s, while LLM-Pruner/FLAP plateau at ~128 tokens/s.
4. **82x512 Configuration**:
- **LLaMA-7B**: Throughput grows from ~128 tokens/s (7s) to ~2048 tokens/s (23s).
- **Ours 4.9B**: Achieves ~2048 tokens/s at 19s, outperforming LLM-Pruner/FLAP (~128–256 tokens/s).
#### Vicuna-13B (Bottom Row)
1. **12x128 Configuration**:
- **Vicuna-13B** (gray): Throughput increases from ~4096 tokens/s (2s) to ~8192 tokens/s (9s).
- **LLM-Pruner 9.2B** (green): Starts at ~256 tokens/s (2s) and reaches ~4096 tokens/s (9s).
- **FLAP 9.5B** (green): Similar to LLM-Pruner (~384 tokens/s at 9s).
- **Ours 9.5B** (blue): Matches LLaMA-7B baseline (~8192 tokens/s at 9s).
2. **82x128 Configuration**:
- **Vicuna-13B**: Throughput rises from ~128 tokens/s (2s) to ~4096 tokens/s (9s).
- **Ours 9.5B**: Matches LLaMA-7B performance (~4096 tokens/s at 9s).
3. **12x512 Configuration**:
- **Vicuna-13B**: Throughput grows from ~256 tokens/s (11s) to ~4096 tokens/s (23s).
- **Ours 9.5B**: Reaches ~4096 tokens/s at 15s, while LLM-Pruner/FLAP lag (~128 tokens/s).
4. **82x512 Configuration**:
- **Vicuna-13B**: Throughput increases from ~128 tokens/s (11s) to ~2048 tokens/s (23s).
- **Ours 9.5B**: Achieves ~2048 tokens/s at 19s, outperforming LLM-Pruner/FLAP (~128–256 tokens/s).
---
### Key Observations
1. **Ours Method Dominance**:
- Consistently achieves **2–4× higher throughput** than baseline models (LLaMA-7B/Vicuna-13B) across all configurations.
- Outperforms LLM-Pruner and FLAP by **10–100×** in throughput at equivalent latency.
2. **Latency-Throughput Tradeoff**:
- All methods show **increasing throughput with latency**, but "Ours" maintains the steepest slope, indicating superior efficiency.
3. **Model-Specific Trends**:
- **LLaMA-7B** underperforms **Vicuna-13B** in smaller configurations (e.g., 12x128), but both converge in larger setups (82x512).
4. **LLM-Pruner vs. FLAP**:
- LLM-Pruner generally matches or slightly exceeds FLAP in throughput, but both lag behind "Ours."
---
### Interpretation
The data demonstrates that the proprietary "Ours" method significantly optimizes throughput while minimizing latency across all token configurations. This suggests advanced optimization techniques (e.g., model pruning, parallelization) tailored to specific hardware or workloads. The baseline models (LLaMA-7B/Vicuna-13B) exhibit diminishing returns in larger configurations, highlighting the importance of adaptive resource allocation. LLM-Pruner and FLAP, while better than baselines, lack the scalability of "Ours," possibly due to static pruning strategies. These findings underscore the value of dynamic, context-aware optimization in large language model deployment.