# Technical Document Extraction: Attention Forward Speed Analysis
## Chart Title
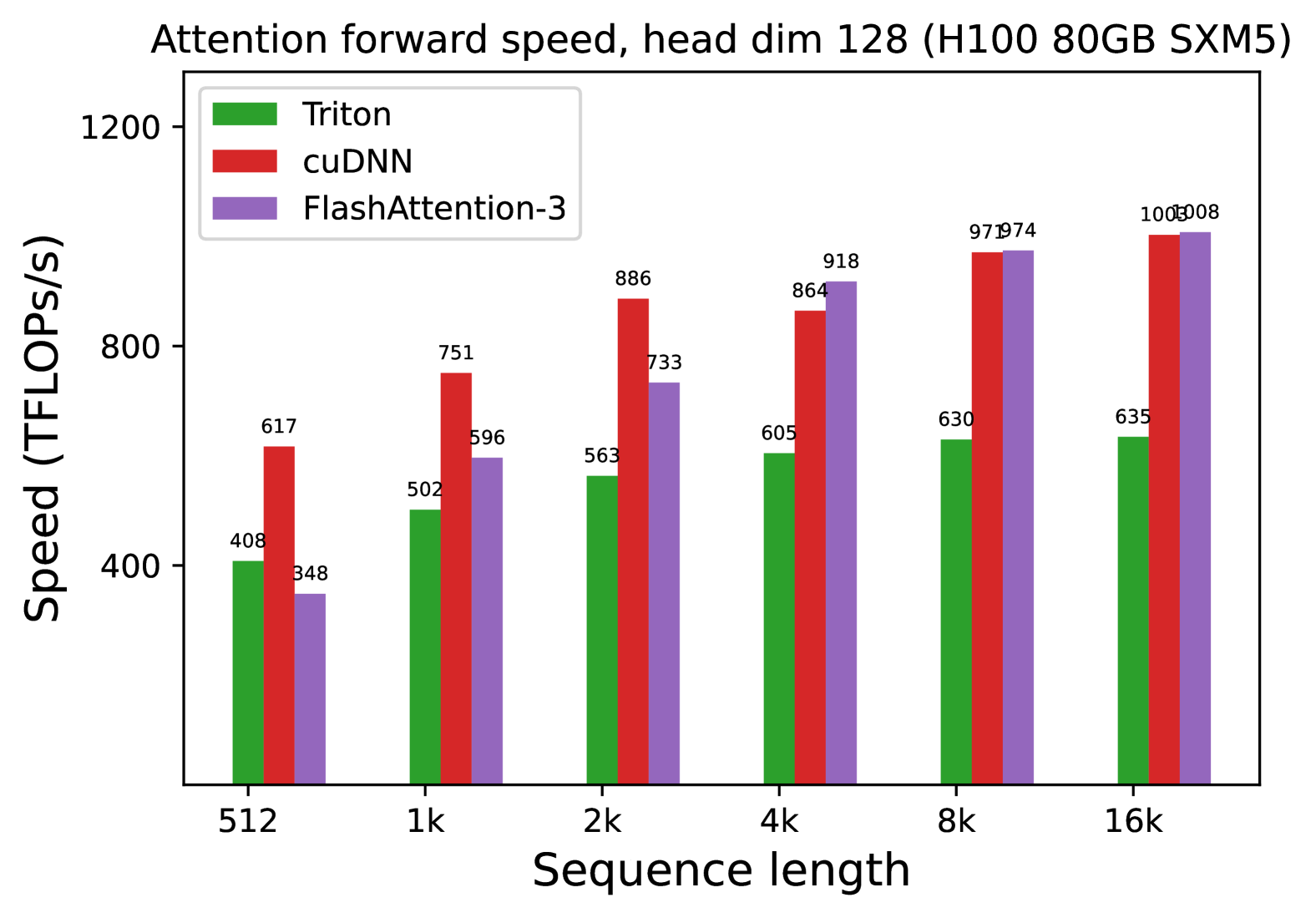
**Attention forward speed, head dim 128 (H100 80GB SXM5)**
### Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
### Legend
- **Triton**: Green
- **cuDNN**: Red
- **FlashAttention-3**: Purple
### Data Points (Speed in TFLOPs/s)
| Sequence Length | Triton | cuDNN | FlashAttention-3 |
|-----------------|--------|-------|------------------|
| 512 | 408 | 617 | 348 |
| 1k | 502 | 751 | 596 |
| 2k | 563 | 886 | 733 |
| 4k | 605 | 864 | 918 |
| 8k | 630 | 971 | 974 |
| 16k | 635 | 1000 | 1008 |
### Key Trends
1. **Triton**:
- Speed increases modestly with sequence length (408 → 635 TFLOPs/s).
- Consistently the lowest performer across all sequence lengths.
2. **cuDNN**:
- Speed increases significantly with sequence length (617 → 1000 TFLOPs/s).
- Outperforms Triton at all sequence lengths.
3. **FlashAttention-3**:
- Speed increases sharply with sequence length (348 → 1008 TFLOPs/s).
- Matches or exceeds cuDNN at 4k, 8k, and 16k sequence lengths.
- Achieves the highest speed at 16k (1008 TFLOPs/s).
### Hardware Context
- GPU: H100 80GB SXM5
- Head dimension: 128
### Observations
- FlashAttention-3 demonstrates superior scalability for longer sequences.
- cuDNN maintains competitive performance but lags behind FlashAttention-3 at 16k.
- Triton shows minimal improvement with increased sequence length.