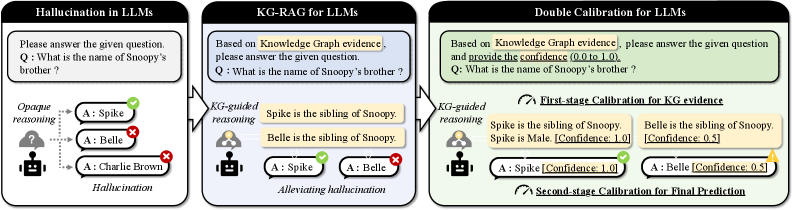
## Diagram: Comparison of Methods to Mitigate Hallucination in LLMs
### Overview
The diagram compares three approaches to address hallucination in Large Language Models (LLMs):
1. **Hallucination in LLMs** (left panel): Demonstrates opaque reasoning leading to incorrect answers.
2. **KG-RAG for LLMs** (center panel): Uses knowledge graph (KG) evidence to guide reasoning and reduce hallucination.
3. **Double Calibration for LLMs** (right panel): Combines KG evidence with confidence scores to refine predictions.
### Components/Axes
- **Panels**: Three vertical sections labeled:
- *Hallucination in LLMs*
- *KG-RAG for LLMs*
- *Double Calibration for LLMs*
- **Elements**:
- **Question**: "What is the name of Snoopy’s brother?" in all panels.
- **Answers**:
- *Hallucination in LLMs*: Spike (✓), Belle (✗), Charlie Brown (✗).
- *KG-RAG for LLMs*: Spike (✓), Belle (✗).
- *Double Calibration for LLMs*: Spike (✓, Confidence: 1.0), Belle (✗, Confidence: 0.5).
- **Reasoning Steps**:
- *KG-guided reasoning* (center panel): "Spike is the sibling of Snoopy."
- *Double Calibration*:
- First-stage: Confidence scores for KG evidence (Spike: 1.0, Belle: 0.5).
- Second-stage: Confidence scores for final prediction (Spike: 1.0, Belle: 0.5).
- **Icons**:
- Robot with a question mark (uncertainty) in the first panel.
- Human figures with thought bubbles (reasoning) in the center and right panels.
### Detailed Analysis
#### Hallucination in LLMs
- **Question**: "What is the name of Snoopy’s brother?"
- **Answers**:
- Spike (correct, marked ✓).
- Belle (incorrect, marked ✗).
- Charlie Brown (incorrect, marked ✗).
- **Reasoning**: Opaque, leading to hallucination (incorrect answers).
#### KG-RAG for LLMs
- **Question**: Same as above.
- **KG-guided reasoning**: "Spike is the sibling of Snoopy."
- **Answers**:
- Spike (correct, marked ✓).
- Belle (incorrect, marked ✗).
- **Flow**: KG evidence directly guides the correct answer.
#### Double Calibration for LLMs
- **Question**: Same as above.
- **First-stage Calibration (KG evidence)**:
- "Spike is the sibling of Snoopy." (Confidence: 1.0).
- "Belle is the sibling of Snoopy." (Confidence: 0.5).
- **Second-stage Calibration (Final Prediction)**:
- Spike (Confidence: 1.0).
- Belle (Confidence: 0.5).
- **Additional Context**: Spike is male (Confidence: 1.0).
### Key Observations
1. **Progression of Accuracy**:
- Opaque reasoning (left) produces hallucinations (incorrect answers).
- KG-guided reasoning (center) reduces hallucination by leveraging structured evidence.
- Double calibration (right) further refines predictions using confidence scores.
2. **Confidence Scores**:
- Spike consistently has the highest confidence (1.0) across methods.
- Belle’s confidence drops from 0.5 (KG evidence) to 0.5 (final prediction), indicating uncertainty.
3. **Flow Direction**:
- Left to right: Increasing reliance on KG evidence and calibration.
### Interpretation
- **Mechanism of Hallucination**: The left panel shows LLMs generating answers without external validation, leading to errors (e.g., Belle and Charlie Brown).
- **Role of KG-RAG**: The center panel demonstrates how integrating knowledge graphs (e.g., "Spike is the sibling of Snoopy") constrains answers to factual data, eliminating incorrect options.
- **Double Calibration**: The right panel introduces confidence scores to quantify uncertainty. By cross-referencing KG evidence (first-stage) and additional attributes (e.g., Spike’s gender), the model achieves higher reliability.
- **Critical Insight**: Combining structured knowledge (KG) with iterative calibration (confidence scoring) significantly mitigates hallucination, as shown by the consistent correctness of "Spike" and quantified confidence.
## Notes
- No non-English text is present.
- All labels and values are explicitly stated in the diagram.
- Spatial grounding: Elements are vertically aligned within panels, with reasoning steps positioned below questions and answers.
- No charts/graphs or numerical trends beyond confidence scores (0.0–1.0).