\n
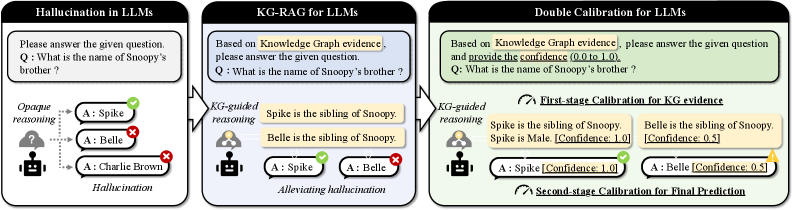
## Diagram: LLM Reasoning Processes - Hallucination, KG-RAG, and Double Calibration
### Overview
The image presents a comparative diagram illustrating three different approaches to reasoning in Large Language Models (LLMs): Hallucination in LLMs, Knowledge Graph-Retrieval Augmented Generation (KG-RAG), and Double Calibration. Each approach is depicted as a flow diagram, showing the question, reasoning process, and answer generated. The diagrams highlight how each method handles the question "What is the name of Snoopy's brother?".
### Components/Axes
Each diagram consists of the following components:
* **Question Box:** A light green box containing the question: "Q: What is the name of Snoopy's brother?".
* **Reasoning Block:** A gray block representing the reasoning process.
* **Answer Blocks:** Two light blue blocks representing potential answers, each with a checkmark (correct) or an 'X' (incorrect).
* **Final Output:** A brown box (in the first diagram) or a text label indicating the final output or calibration stage.
* **Icons:** Human icons representing the LLM and knowledge sources.
### Detailed Analysis or Content Details
**1. Hallucination in LLMs (Left Diagram)**
* **Question:** "Q: What is the name of Snoopy's brother?"
* **Reasoning:** "Opaque reasoning" is indicated within the gray block. A question mark icon represents the reasoning process.
* **Answers:**
* A: Spike (marked with a red 'X' - incorrect)
* A: Belle (marked with a red 'X' - incorrect)
* **Final Output:** "Charlie Brown" is presented in a brown box labeled "Hallucination".
**2. KG-RAG for LLMs (Center Diagram)**
* **Question:** "Q: What is the name of Snoopy's brother?"
* **Reasoning:** "KG-guided reasoning" is indicated within the gray block. Two human icons are shown, one with a knowledge graph symbol.
* **Knowledge Graph Evidence:**
* "Spike is the sibling of Snoopy."
* "Belle is the sibling of Snoopy."
* **Answers:**
* A: Spike (marked with a green checkmark - correct)
* A: Belle (marked with a green checkmark - correct)
* **Final Output:** "Alleviating hallucination" is indicated.
**3. Double Calibration for LLMs (Right Diagram)**
* **Question:** "Q: What is the name of Snoopy's brother?"
* **Reasoning:** "KG-guided reasoning" is indicated within the gray block. Two human icons are shown, one with a knowledge graph symbol.
* **First-stage Calibration for KG evidence:**
* "Spike is the sibling of Snoopy." - Spike is Male [Confidence: 1.0] (marked with a green checkmark)
* "Belle is the sibling of Snoopy." - Belle is Female [Confidence: 0.5] (marked with a yellow triangle)
* **Answers:**
* A: Spike [Confidence: 1.0] (marked with a green checkmark)
* A: Belle [Confidence: 0.5] (marked with a yellow triangle)
* **Second-stage Calibration for Final Prediction:** is indicated below the answers.
### Key Observations
* The "Hallucination" diagram demonstrates the LLM generating an incorrect answer ("Charlie Brown") without relying on external knowledge.
* The "KG-RAG" diagram shows the LLM leveraging a knowledge graph to identify both correct answers ("Spike" and "Belle").
* The "Double Calibration" diagram introduces a confidence score for each answer, with "Spike" having a higher confidence (1.0) than "Belle" (0.5). This suggests a mechanism for prioritizing more reliable answers.
* The use of checkmarks, 'X' marks, and confidence scores visually indicates the accuracy and reliability of the answers.
### Interpretation
The diagrams illustrate a progression in LLM reasoning techniques aimed at mitigating the problem of "hallucination" – the generation of factually incorrect or nonsensical information. The first diagram highlights the vulnerability of a standard LLM to generating incorrect responses. The second diagram demonstrates how integrating a knowledge graph (KG-RAG) can significantly improve accuracy by grounding the LLM's reasoning in verifiable facts. The third diagram introduces a further refinement – double calibration – which not only leverages a knowledge graph but also assigns confidence scores to the retrieved information, allowing for a more nuanced and reliable final prediction.
The confidence scores in the "Double Calibration" diagram suggest a probabilistic approach to reasoning, where the LLM doesn't simply provide a single answer but rather a ranked list of possibilities with associated probabilities. This is a significant step towards building more trustworthy and explainable AI systems. The use of color-coding (green for correct, red for incorrect, yellow for uncertain) provides a clear visual representation of the system's confidence in its answers. The diagrams collectively demonstrate a shift from opaque, potentially unreliable reasoning to a more transparent, knowledge-grounded, and calibrated approach.