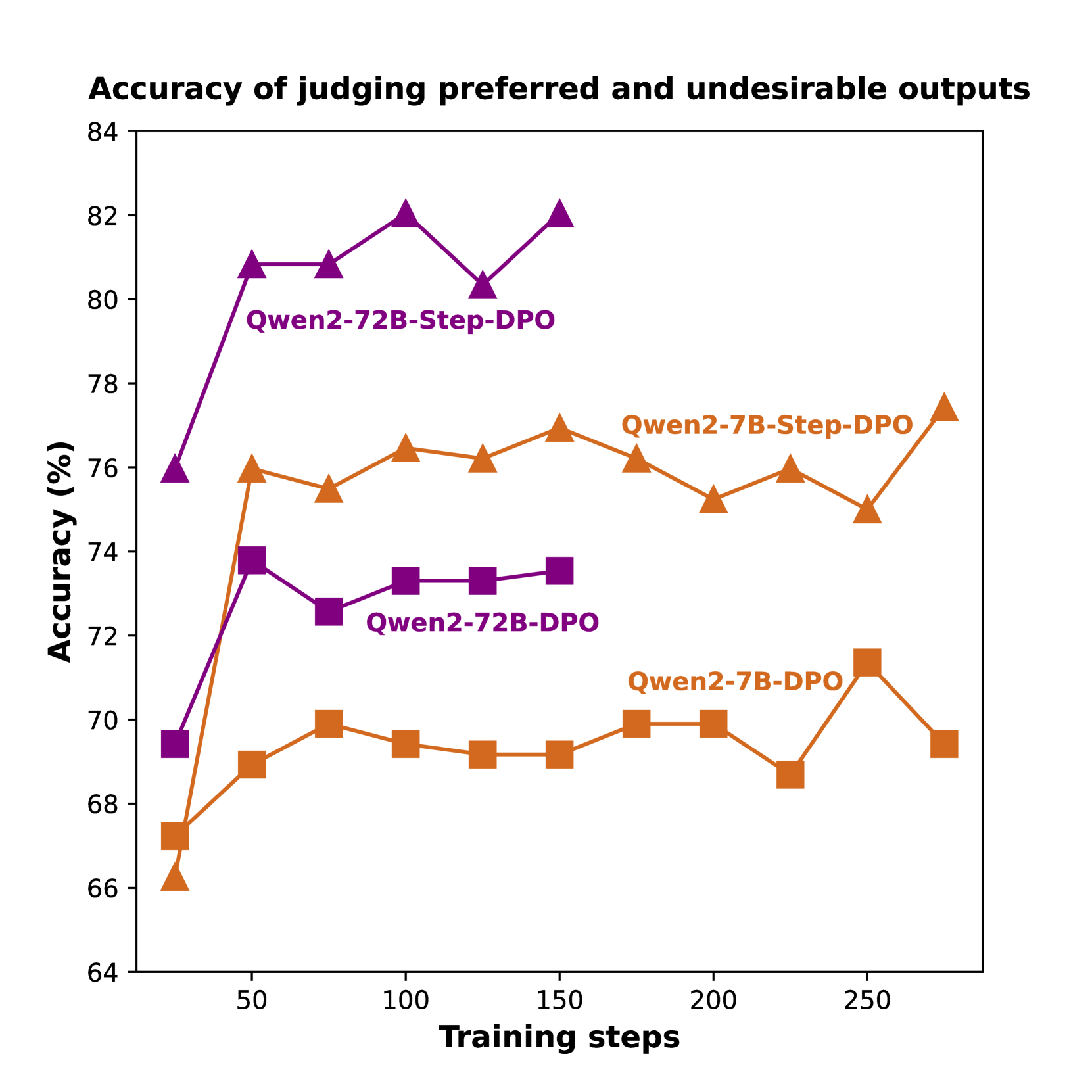
## Line Chart: Accuracy of judging preferred and undesirable outputs
### Overview
The chart compares the accuracy of three model configurations (Qwen2-72B-Step-DPO, Qwen2-72B-DPO, Qwen2-7B-DPO) across training steps, showing how accuracy evolves during training. Three distinct lines with different markers and colors represent each configuration.
### Components/Axes
- **X-axis**: Training steps (50-250, increments of 50)
- **Y-axis**: Accuracy (%) (64-84, increments of 2)
- **Legend**:
- Purple triangles: Qwen2-72B-Step-DPO
- Orange squares: Qwen2-72B-DPO
- Orange diamonds: Qwen2-7B-DPO
- **Title**: "Accuracy of judging preferred and undesirable outputs"
### Detailed Analysis
1. **Qwen2-72B-Step-DPO (Purple triangles)**:
- Starts at 76% accuracy at 50 steps
- Peaks at 82% at 100 steps
- Dips to 80% at 150 steps
- Rises to 82% at 200 steps
- Final accuracy: 82% at 250 steps
2. **Qwen2-72B-DPO (Orange squares)**:
- Starts at 67% at 50 steps
- Rises to 72% at 100 steps
- Stabilizes between 72-73% from 100-250 steps
3. **Qwen2-7B-DPO (Orange diamonds)**:
- Starts at 66% at 50 steps
- Increases to 71% at 100 steps
- Fluctuates between 69-71% through 250 steps
### Key Observations
- Step-DPO models consistently outperform DPO-only models
- 72B-Step-DPO achieves highest accuracy (82%)
- 7B-DPO shows gradual improvement but plateaus below 72%
- All models show diminishing returns after 150 steps
- 72B-Step-DPO maintains >76% accuracy throughout training
### Interpretation
The data demonstrates that the Step-DPO training methodology significantly improves output judgment accuracy compared to standard DPO. The 72B-Step-DPO configuration achieves the highest performance, suggesting that both model size and training methodology are critical factors. The 7B-DPO's lower performance highlights the importance of model capacity in complex judgment tasks. The plateauing trends across all models after 150 steps indicate potential optimization limits in the current training framework. The Step-DPO's incremental approach appears to enable more nuanced learning, particularly evident in the 72B model's sustained high performance.