\n
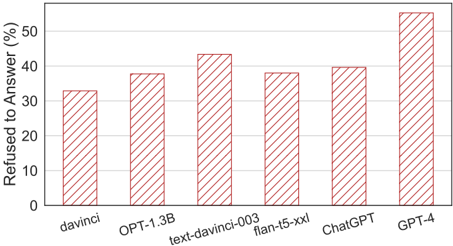
## Bar Chart: Refusal to Answer Rate by Language Model
### Overview
This image presents a bar chart comparing the percentage of times different language models refused to answer a question. The x-axis lists the language models, and the y-axis represents the refusal rate in percentage. All bars are filled with a light red diagonal hatch pattern.
### Components/Axes
* **X-axis Label:** Language Models (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4)
* **Y-axis Label:** Refused to Answer (%)
* **Y-axis Scale:** 0% to 60% in increments of 10%.
* **Bar Color:** Light red with diagonal hatching.
### Detailed Analysis
The chart displays the refusal rate for each language model. The trend is generally increasing from left to right, with GPT-4 exhibiting the highest refusal rate.
* **davinci:** Approximately 34% refusal rate.
* **OPT-1.3B:** Approximately 38% refusal rate.
* **text-davinci-003:** Approximately 44% refusal rate.
* **flan-t5-xxl:** Approximately 39% refusal rate.
* **ChatGPT:** Approximately 41% refusal rate.
* **GPT-4:** Approximately 55% refusal rate.
### Key Observations
* GPT-4 has a significantly higher refusal rate compared to all other models.
* davinci has the lowest refusal rate among the models presented.
* The refusal rates generally increase with model complexity, although flan-t5-xxl is an exception.
### Interpretation
The data suggests that more advanced language models, particularly GPT-4, are more likely to refuse to answer questions. This could be due to several factors, including:
* **Increased safety constraints:** Newer models may have stricter guidelines to avoid generating harmful or inappropriate responses.
* **Improved awareness of limitations:** More sophisticated models may be better at recognizing when they lack the knowledge or ability to provide a reliable answer.
* **Alignment with human values:** Models may be trained to refuse questions that are ethically questionable or violate certain principles.
The increasing refusal rate with model complexity indicates a trade-off between helpfulness and safety. While more advanced models can provide more comprehensive and nuanced responses, they may also be more cautious and less willing to engage with certain types of queries. The lower refusal rate of davinci could indicate less stringent safety measures or a less sophisticated understanding of potential risks. The anomaly of flan-t5-xxl having a lower refusal rate than ChatGPT and text-davinci-003 suggests that its training or architecture may lead to different behavior regarding question refusal.