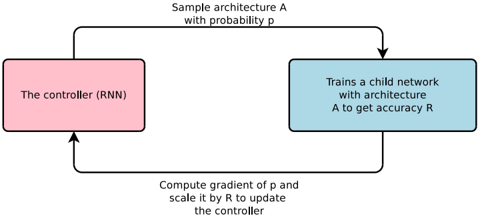
## Diagram: Controller-Based Neural Architecture Search
### Overview
The image presents a diagram illustrating a controller-based neural architecture search process. It depicts a loop where a controller (RNN) samples architectures, trains child networks, and updates itself based on the performance of those networks.
### Components/Axes
* **The controller (RNN):** A pink rounded rectangle on the left side of the diagram.
* **Trains a child network with architecture A to get accuracy R:** A light blue rounded rectangle on the right side of the diagram.
* **Sample architecture A with probability p:** Text above the top arrow, indicating the controller samples architectures with a certain probability.
* **Compute gradient of p and scale it by R to update the controller:** Text below the bottom arrow, indicating the controller updates itself based on the gradient of the probability and the accuracy of the child network.
### Detailed Analysis
The diagram shows a cyclical process:
1. The controller (RNN) samples an architecture A with probability p. This is represented by an arrow going from the pink controller box to the light blue "Trains a child network" box.
2. The child network is trained with architecture A, resulting in accuracy R.
3. The gradient of p is computed and scaled by R to update the controller. This is represented by an arrow going from the light blue "Trains a child network" box back to the pink controller box.
### Key Observations
* The diagram illustrates a reinforcement learning approach to neural architecture search.
* The controller learns to sample architectures that lead to high accuracy in the child networks.
* The accuracy R is used as a reward signal to update the controller.
### Interpretation
The diagram illustrates a common method for automating neural architecture search. The controller, typically an RNN, learns to generate promising architectures. The performance of these architectures, evaluated by training child networks, is used to refine the controller's search strategy. This process allows for the discovery of novel and effective neural network architectures without extensive manual design. The use of the gradient of 'p' scaled by 'R' suggests a policy gradient reinforcement learning approach.