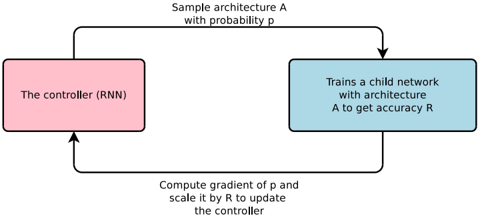
## Diagram: Reinforcement Learning Architecture for Neural Architecture Search
### Overview
The diagram illustrates a reinforcement learning (RL) framework for neural architecture search (NAS). It depicts a closed-loop system where a controller (RNN) samples neural network architectures, trains child networks, and updates itself based on performance feedback. The process involves probabilistic sampling, gradient computation, and policy optimization.
### Components/Axes
1. **Controller (RNN)**
- Represented as a pink rectangle on the left.
- Labeled explicitly as "The controller (RNN)".
- Receives input from the gradient computation step and outputs architecture sampling probabilities.
2. **Child Network Training**
- Represented as a blue rectangle on the right.
- Labeled "Trains a child network with architecture A to get accuracy R".
- Outputs accuracy metric `R` for the sampled architecture `A`.
3. **Arrows and Transitions**
- **Top Arrow**: "Sample architecture A with probability p"
- Connects the controller to the child network training block.
- Indicates probabilistic sampling of architectures.
- **Bottom Arrow**: "Compute gradient of p and scale it by R to update the controller"
- Connects the child network training block back to the controller.
- Describes the policy gradient update mechanism.
### Detailed Analysis
- **Controller (RNN)**:
- Acts as the policy network in RL.
- Outputs a probability distribution `p` over possible architectures `A`.
- Updated via gradient ascent using the product of the gradient of `p` and the accuracy `R`.
- **Child Network Training**:
- Trains a network with architecture `A` sampled from `p`.
- Evaluates performance via accuracy `R`.
- Provides scalar feedback (`R`) to the controller.
- **Gradient Computation**:
- The gradient of the sampling probability `p` is computed.
- Scaled by the accuracy `R` to adjust the controller’s policy.
- This step implements the REINFORCE algorithm for policy optimization.
### Key Observations
1. **Closed-Loop System**: The diagram shows a cyclical process where the controller iteratively improves its architecture-sampling policy based on child network performance.
2. **Probabilistic Sampling**: Architectures are not deterministically selected but sampled stochastically, enabling exploration of the search space.
3. **Gradient Scaling**: The update rule explicitly ties the controller’s policy gradient to the child network’s accuracy, emphasizing reward-driven learning.
4. **No Numerical Values**: The diagram lacks specific numerical data (e.g., exact values of `p` or `R`), focusing instead on the algorithmic flow.
### Interpretation
This diagram represents a **policy gradient-based NAS framework**. The controller (RNN) learns to sample architectures that maximize expected accuracy by:
1. Sampling architectures probabilistically (`p`).
2. Training child networks to evaluate their performance (`R`).
3. Updating the policy via gradient ascent using `∇p * R`.
The absence of numerical data suggests this is a high-level conceptual diagram, emphasizing the interaction between components rather than implementation details. The use of an RNN as the controller implies sequential decision-making, where the policy may depend on historical sampling outcomes. The gradient scaling by `R` ensures that only architectures leading to higher accuracy reinforce the controller’s policy, aligning with reinforcement learning principles.
**Notable Design Choices**:
- The pink/blue color coding distinguishes the controller (policy) from the training process (environment).
- The bidirectional flow highlights the feedback loop central to RL.
- The explicit mention of "probability p" and "gradient of p" underscores the stochastic and differentiable nature of the search process.