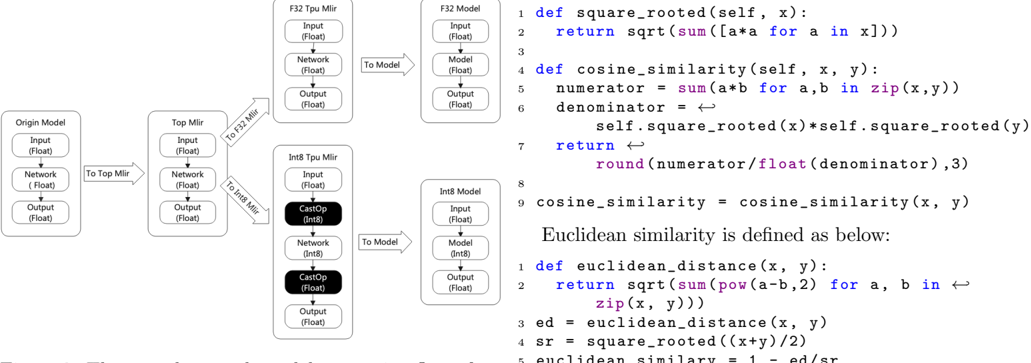
## Hybrid Diagram and Code Snippet: Model Conversion Pipeline and Similarity Metrics
### Overview
The image displays a technical workflow diagram on the left and Python code snippets on the right. The diagram illustrates a machine learning model conversion pipeline, specifically showing the transition from an "Origin Model" to hardware-optimized formats (F32 and Int8). The code snippets provide Python implementations for calculating Cosine Similarity and Euclidean Similarity, likely used to validate the accuracy of these model conversions.
### Components/Axes
#### Diagram (Left Side)
The diagram is a flowchart consisting of rectangular nodes connected by directional arrows.
* **Origin Model (Far Left):**
* Contains: Input (Float) -> Network (Float) -> Output (Float).
* **Top Mlir (Center Left):**
* Contains: Input (Float) -> Network (Float) -> Output (Float).
* Connected from "Origin Model" via arrow labeled "To Top Mlir".
* **F32 Tpu Mlir (Top Center):**
* Contains: Input (Float) -> Network (Float) -> Output (Float).
* Connected from "Top Mlir" via arrow labeled "To F32 Mlir".
* **F32 Model (Top Right):**
* Contains: Input (Float) -> Model (Float) -> Output (Float).
* Connected from "F32 Tpu Mlir" via arrow labeled "To Model".
* **Int8 Tpu Mlir (Bottom Center):**
* Contains: Input (Float) -> **CastOp (Int8)** -> Network (Int8) -> **CastOp (Float)** -> Output (Float).
* *Note:* The "CastOp" boxes are black with white text, distinguishing them from the white boxes.
* Connected from "Top Mlir" via arrow labeled "To Int8 Mlir".
* **Int8 Model (Bottom Right):**
* Contains: Input (Int8) -> Model (Int8) -> Output (Float).
* Connected from "Int8 Tpu Mlir" via arrow labeled "To Model".
#### Code (Right Side)
The code is presented in two distinct blocks.
* **Block 1 (Cosine Similarity):**
* `def square_rooted(self, x):`
* `return sqrt(sum([a*a for a in x]))`
* `def cosine_similarity(self, x, y):`
* `numerator = sum(a*b for a,b in zip(x,y))`
* `denominator = self.square_rooted(x)*self.square_rooted(y)`
* `return round(numerator/float(denominator),3)`
* `cosine_similarity = cosine_similarity(x, y)`
* **Block 2 (Euclidean Similarity):**
* Text: "Euclidean similarity is defined as below:"
* `def euclidean_distance(x, y):`
* `return sqrt(sum(pow(a-b,2) for a, b in zip(x, y)))`
* `ed = euclidean_distance(x, y)`
* `sr = square_rooted((x+y)/2)`
* `euclidean_similary = 1 - ed/sr`
### Detailed Analysis
#### Diagram Flow
1. **Origin to Intermediate:** The process begins at the "Origin Model" and flows into the "Top Mlir" (MLIR - Multi-Level Intermediate Representation).
2. **Branching:** The "Top Mlir" acts as a hub, branching into two distinct optimization paths:
* **F32 Path:** Maintains floating-point precision throughout the conversion to the "F32 Model".
* **Int8 Path:** Introduces quantization. The "Int8 Tpu Mlir" node explicitly shows the insertion of `CastOp` layers. These layers convert the data from Float to Int8 before the network processing, and back to Float after processing, before reaching the "Int8 Model".
3. **Hardware Targeting:** The final nodes ("F32 Model" and "Int8 Model") represent the final compiled models ready for deployment on TPU hardware.
#### Code Logic
* **Cosine Similarity:** This implementation calculates the cosine of the angle between two vectors (`x` and `y`). It uses a standard dot product divided by the product of the magnitudes (Euclidean norms) of the vectors. The result is rounded to 3 decimal places.
* **Euclidean Similarity:** This implementation calculates a normalized distance.
* It first calculates the Euclidean distance (`ed`).
* It calculates a scaling factor (`sr`) based on the square root of the average of the inputs.
* It defines similarity as `1 - (distance / scaling_factor)`.
* *Note:* There is a typo in the variable name `euclidean_similary` (missing the 'i' before 'ty').
### Key Observations
* **Quantization Overhead:** The diagram visually highlights the complexity of the Int8 path compared to the F32 path. The inclusion of `CastOp` (black boxes) indicates that quantization requires explicit data type conversion layers, which are absent in the F32 path.
* **Typo:** The code contains a spelling error in the variable name `euclidean_similary`.
* **Data Flow:** The diagram clearly distinguishes between the data types (Float vs. Int8) at each stage of the pipeline.
### Interpretation
This image depicts a standard **Model Quantization Pipeline**.
* **Why this matters:** When deploying machine learning models to hardware (like TPUs), developers often convert models from high-precision (Float32) to lower-precision (Int8) to reduce memory footprint and increase inference speed.
* **The "CastOp" significance:** The black boxes in the diagram represent the necessary "glue" code or operations required to handle the data type mismatch between the input/output and the quantized network layers.
* **The Code's Role:** The Python code is likely a **Model Validation Script**. After converting a model to Int8, the output of the quantized model will differ slightly from the original Float32 model due to precision loss. The provided code calculates the similarity between the outputs of the "Origin Model" and the "Int8 Model" (or "F32 Model"). If the similarity score is too low, the quantization process may be deemed unsuccessful or requiring further calibration. The use of both Cosine and Euclidean similarity suggests a multi-faceted approach to measuring "model drift."