\n
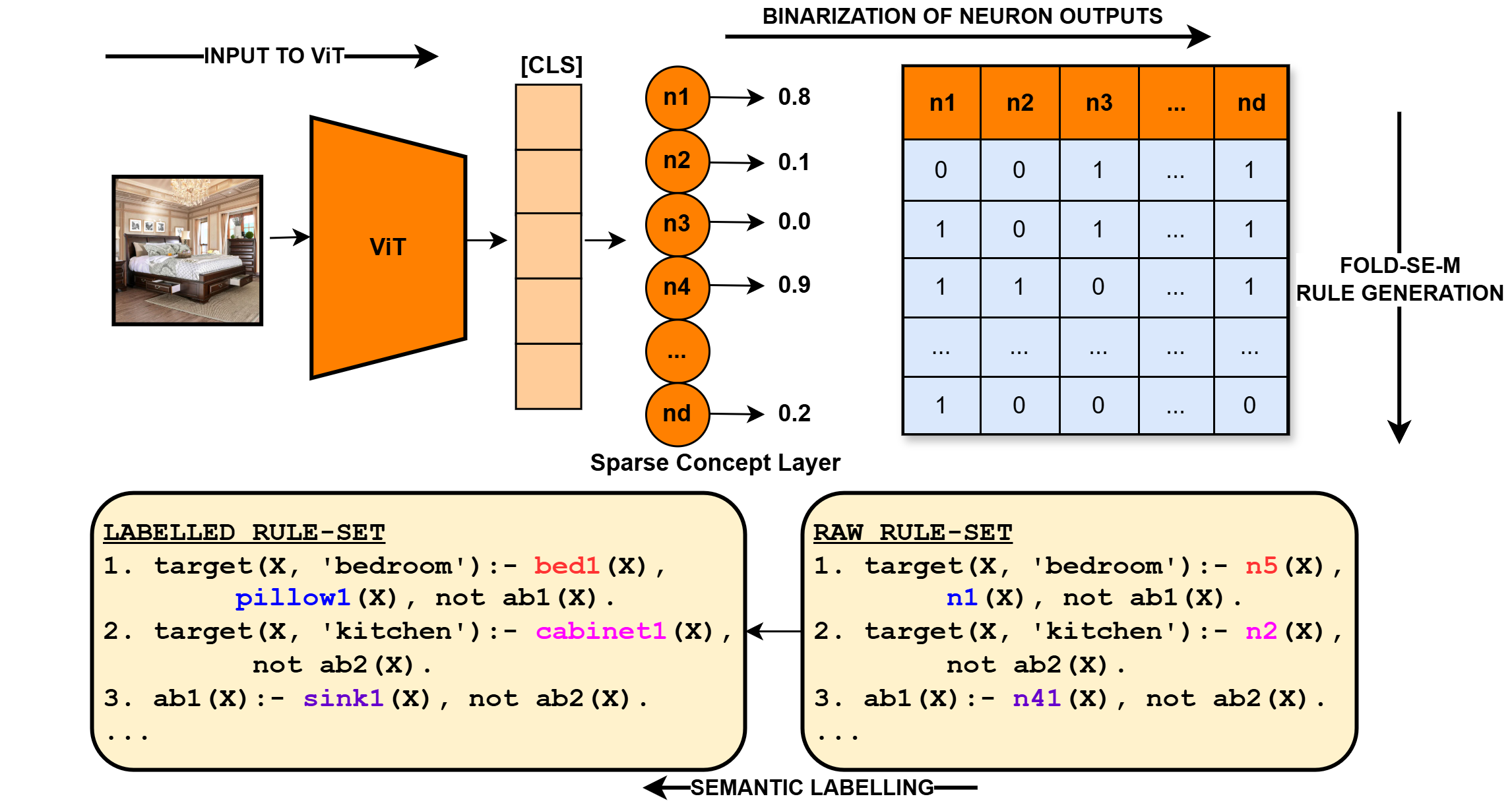
## Diagram: Visualizing Rule Generation from Image Input
### Overview
This diagram illustrates a process for generating rules from image input using a Vision Transformer (ViT) model, a sparse concept layer, and a Fold-SE-M rule generation component. The process involves inputting an image, extracting features with ViT, binarizing neuron outputs, and then generating labeled and raw rule sets through semantic labeling.
### Components/Axes
The diagram consists of the following key components:
* **Input Image:** A photograph of a bedroom scene.
* **ViT (Vision Transformer):** A red rectangular block representing the image feature extractor.
* **Sparse Concept Layer:** A series of circles labeled `n1`, `n2`, `n3`, `n4`, ..., `nd`, representing neurons with associated confidence scores.
* **Binarization of Neuron Outputs:** A rectangular table showing the binary (0 or 1) outputs of the neurons.
* **Fold-SE-M Rule Generation:** A rectangular block indicating the rule generation process.
* **Labelled Rule-Set:** A block of text listing rules with semantic labels.
* **Raw Rule-Set:** A block of text listing rules without semantic labels.
* **Arrows:** Indicate the flow of information between components.
* **[CLS]**: A label indicating the classification token.
### Detailed Analysis or Content Details
**1. Input to ViT:**
* The input is an image of a bedroom. The image shows a bed, a window, and other furniture.
**2. ViT Output & Sparse Concept Layer:**
* The ViT model processes the image and outputs features to the Sparse Concept Layer.
* The Sparse Concept Layer consists of neurons `n1` through `nd`.
* The confidence scores associated with each neuron are as follows (approximate values):
* `n1`: 0.8
* `n2`: 0.1
* `n3`: 0.0
* `n4`: 0.9
* `nd`: 0.2
**3. Binarization of Neuron Outputs:**
* The neuron outputs are binarized (converted to 0 or 1). The table shows the binary outputs for neurons `n1` through `nd`.
* The table has columns `n1`, `n2`, `n3`, `n4`, and `nd` (and more, indicated by "...").
* The table has rows of binary values (0 or 1).
* Example values:
* `n1`: 0, 1, 1, 1, ... , 1
* `n2`: 0, 0, 1, 1, ... , 1
* `n3`: 1, 0, 1, 0, ... , 0
* `n4`: 1, 1, 0, 1, ... , 1
* `nd`: 1, 0, 0, 0, ... , 0
**4. Labelled Rule-Set:**
* The labelled rule-set contains rules with semantic labels.
* Example rules:
1. `target(X, 'bedroom') :- bed1(X), pillow1(X), not ab1(X).`
2. `target(X, 'kitchen') :- cabinet1(X), not ab2(X).`
3. `ab1(X) :- sink1(X), not ab2(X).`
**5. Raw Rule-Set:**
* The raw rule-set contains rules without semantic labels.
* Example rules:
1. `target(X, 'bedroom') :- n5(X), n1(X), not ab1(X).`
2. `target(X, 'kitchen') :- n2(X), not ab2(X).`
3. `ab1(X) :- n41(X), not ab2(X).`
**6. Semantic Labelling:**
* An arrow labeled "SEMANTIC LABELLING" connects the Raw Rule-Set to the Labelled Rule-Set, indicating the process of adding semantic labels to the rules.
**7. Fold-SE-M Rule Generation:**
* An arrow labeled "FOLD-SE-M RULE GENERATION" points from the Binarization of Neuron Outputs to the Fold-SE-M Rule Generation block.
### Key Observations
* The confidence scores of the neurons vary significantly, suggesting that some neurons are more strongly activated by the input image than others.
* The binarization process converts the continuous confidence scores into discrete binary values, which may result in information loss.
* The labelled rule-set provides more interpretable rules by associating semantic labels with the concepts.
* The raw rule-set uses neuron identifiers (e.g., `n5(X)`) instead of semantic labels.
### Interpretation
This diagram illustrates a pipeline for converting visual information into symbolic rules. The ViT model extracts features from the image, and the sparse concept layer represents these features as a set of neurons. The binarization step creates a discrete representation of the neuron activations, which is then used to generate rules. The semantic labelling process adds meaning to the rules, making them more interpretable. The overall goal is to create a system that can reason about images and generate logical rules based on their content. The difference between the "Labelled Rule-Set" and the "Raw Rule-Set" suggests a process of mapping neuron activations to human-understandable concepts. The varying confidence scores of the neurons indicate that the system is able to identify different concepts with varying degrees of certainty. The use of "not" in the rules suggests that the system is also able to identify the absence of certain concepts. This system could be used for tasks such as visual question answering, image captioning, or robot navigation.