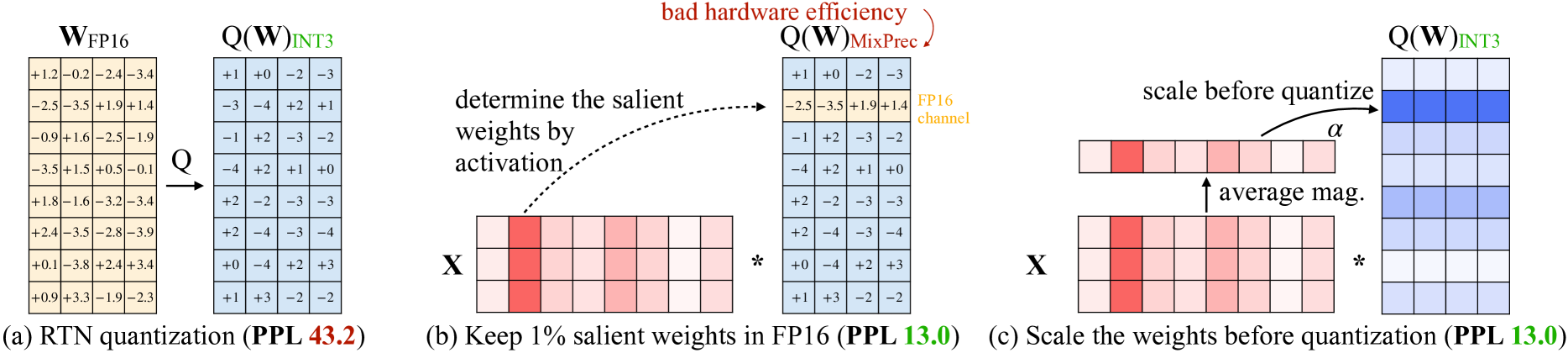
# Technical Analysis: Weight Quantization Strategies for Neural Networks
This image illustrates three different approaches to weight quantization in neural networks, comparing Round-to-Nearest (RTN) quantization, Mixed-Precision quantization, and Activation-aware Weight Quantization (AWQ). The diagrams focus on the relationship between weights ($W$), activations ($X$), and the resulting Perplexity (PPL) metric.
---
## Section (a): RTN Quantization
**Caption:** (a) RTN quantization (**PPL 43.2**)
This section demonstrates a standard Round-to-Nearest (RTN) quantization process.
### 1. Components
* **$W_{FP16}$ (Input Matrix):** An $8 \times 4$ matrix of high-precision floating-point weights (tan background).
* **Operator $Q$:** An arrow indicating the quantization function.
* **$Q(W)_{INT3}$ (Output Matrix):** An $8 \times 4$ matrix of 3-bit integer weights (light blue background).
### 2. Data Table: Weight Values
| Row | $W_{FP16}$ (Original) | $Q(W)_{INT3}$ (Quantized) |
| :--- | :--- | :--- |
| 1 | [+1.2, -0.2, -2.4, -3.4] | [+1, +0, -2, -3] |
| 2 | [-2.5, -3.5, +1.9, +1.4] | [-3, -4, +2, +1] |
| 3 | [-0.9, +1.6, -2.5, -1.9] | [-1, +2, -3, -2] |
| 4 | [-3.5, +1.5, +0.5, -0.1] | [-4, +2, +1, +0] |
| 5 | [+1.8, -1.6, -3.2, -3.4] | [+2, -2, -3, -3] |
| 6 | [+2.4, -3.5, -2.8, -3.9] | [+2, -4, -3, -4] |
| 7 | [+0.1, -3.8, +2.4, +3.4] | [+0, -4, +2, +3] |
| 8 | [+0.9, +3.3, -1.9, -2.3] | [+1, +3, -2, -2] |
**Trend:** The quantization maps continuous values to the nearest integer within a 3-bit range (likely -4 to +3). This results in a high Perplexity of **43.2**, indicating significant information loss.
---
## Section (b): Mixed-Precision Quantization
**Caption:** (b) Keep 1% salient weights in FP16 (**PPL 13.0**)
This section illustrates a "Mixed-Precision" approach where important weights are kept in high precision.
### 1. Components
* **Matrix $X$ (Activations):** A $2 \times 8$ matrix. One column (the 2nd column) is highlighted in dark red, indicating high activation magnitude ("salient").
* **Matrix $Q(W)_{MixPrec}$:** An $8 \times 4$ matrix where most values are INT3 (blue), but one row (the 2nd row) is kept in FP16 (tan).
* **Annotation 1:** A dashed arrow from the salient activation column to the FP16 weight row with the text: *"determine the salient weights by activation"*.
* **Annotation 2:** A red curved arrow pointing to the FP16 row with the text: *"bad hardware efficiency"*.
* **Label:** The FP16 row is labeled *"FP16 channel"* in gold text.
### 2. Logic and Flow
* The system identifies that the 2nd column of activations ($X$) has high values.
* To minimize error, the corresponding 2nd row of weights is not quantized, remaining as: `[-2.5, -3.5, +1.9, +1.4]`.
* **Result:** Perplexity improves significantly to **13.0**, but the non-uniform data types lead to poor hardware efficiency.
---
## Section (c): Activation-aware Weight Quantization (AWQ)
**Caption:** (c) Scale the weights before quantization (**PPL 13.0**)
This section illustrates the AWQ method, which achieves the same accuracy as mixed-precision but maintains a uniform INT3 format.
### 1. Components
* **Matrix $X$ (Activations):** Same as section (b), showing a salient 2nd column.
* **Average Mag. Vector:** A $1 \times 8$ vector derived from $X$ representing the average magnitude of activations per channel.
* **Scaling Vector $\alpha$:** A $1 \times 8$ vector used to scale the weights.
* **$Q(W)_{INT3}$ (Output Matrix):** A uniform $8 \times 4$ INT3 matrix. The 2nd row is highlighted in a darker blue to indicate it was scaled before quantization.
* **Annotation:** An arrow from the $\alpha$ vector to the weight matrix with the text: *"scale before quantize"*.
### 2. Logic and Flow
1. **Analyze Activations:** Calculate the "average mag." of activations ($X$).
2. **Calculate Scaling Factor:** Derive a scaling factor $\alpha$ based on activation importance.
3. **Apply Scaling:** The weights in the salient channel (Row 2) are scaled up before the quantization process.
4. **Quantize:** All weights are quantized to INT3.
5. **Result:** This method achieves the same low Perplexity (**13.0**) as mixed-precision but allows the entire weight matrix to remain in a hardware-friendly INT3 format.
---
## Summary of Performance Metrics
| Method | Format | Perplexity (PPL) | Hardware Efficiency |
| :--- | :--- | :--- | :--- |
| (a) RTN | Pure INT3 | 43.2 (Poor) | High |
| (b) Mixed-Precision | INT3 + FP16 | 13.0 (Good) | Low |
| (c) AWQ (Proposed) | Pure INT3 | 13.0 (Good) | High |