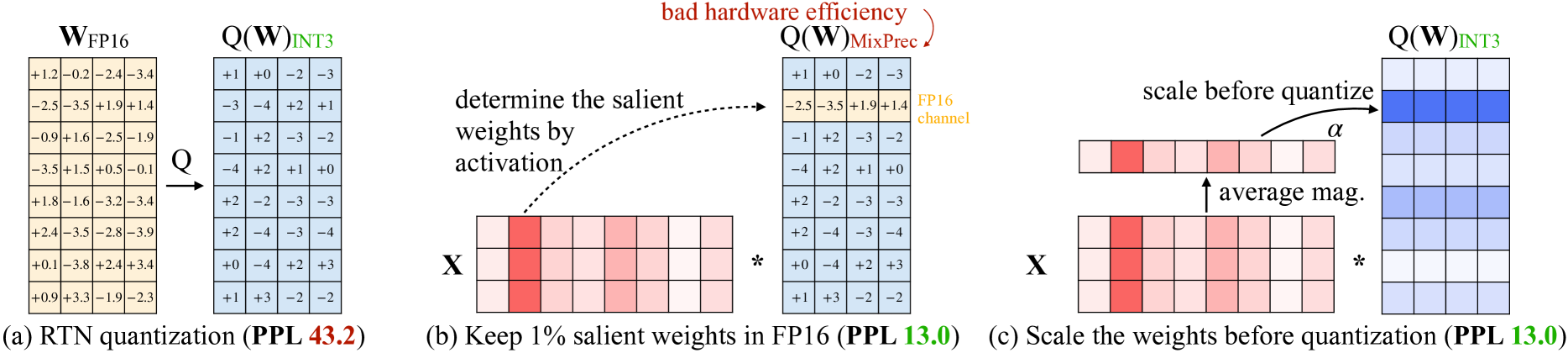
# Technical Analysis of Quantization Methods in Neural Networks
## Panel (a): RTN Quantization (PPL 43.2)
### Components:
- **Input Matrix**: `W_FP16` (original 8x8 weight matrix in 16-bit floating point)
```
+1.2 -0.2 -2.4 -3.4
-2.5 -3.5 +1.9 +1.4
-0.9 +1.6 -2.5 -1.9
-3.5 +1.5 +0.5 -0.1
+1.8 -1.6 -3.2 -3.4
+2.4 -3.5 -2.8 -3.9
+0.1 -3.8 +2.4 +3.4
+0.9 +3.3 -1.9 -2.3
```
- **Quantized Output**: `Q(W)_INT3` (8x8 matrix in 3-bit integer format)
```
+1 +0 -2 -3
-3 -4 +2 +1
-1 +2 -3 -2
-4 +2 +1 +0
+2 -2 -3 -3
+2 -4 -3 -4
+0 -4 +2 +3
+1 +3 -2 -2
```
- **Transformation**: `Q(W)_INT3` derived via quantization-aware training (RTN)
- **Key Annotation**: "RTN quantization" with perplexity (PPL) metric 43.2
## Panel (b): Salient Weight Preservation (PPL 13.0)
### Process Flow:
1. **Activation-Driven Selection**:
- **Input**: Original weights `W_FP16` multiplied by activation matrix `X`
- **Highlighted Weights**: Red-shaded weights (1% of total) identified as "salient"
- **Example Highlighted Weights**:
- Row 1: `+1.2` (first column)
- Row 2: `-3.5` (second column)
- Row 3: `+1.6` (second column)
- Row 4: `+0.5` (third column)
- Row 5: `+1.8` (first column)
- Row 6: `+2.4` (first column)
- Row 7: `-3.8` (second column)
- Row 8: `+3.3` (second column)
2. **Quantization Strategy**:
- **Mixed Precision**: FP16 retained for salient weights
- **Quantization**: Non-salient weights quantized to INT3
- **Visualization**:
- Blue matrix: `Q(W)_INT3` (quantized)
- Red-highlighted cells: FP16-preserved salient weights
## Panel (c): Scaling-Aware Quantization (PPL 13.0)
### Process Flow:
1. **Pre-Quantization Scaling**:
- **Scaling Factor (α)**: Calculated as average magnitude of weights
- **Scaling Operation**:
```
X (original weights) * α → Scaled weights
```
- **Example Scaling**:
- Red-shaded weights (high magnitude) scaled up
- Blue-shaded weights (low magnitude) scaled down
2. **Quantization**:
- **Method**: `Q(W)_INT3` applied to scaled weights
- **Visualization**:
- Top matrix: Scaled weights before quantization
- Bottom matrix: Quantized weights (`Q(W)_INT3`)
### Key Observations:
- **Hardware Efficiency**: Red text highlights "bad hardware efficiency" trade-off
- **Color Coding**:
- Red: High-magnitude weights (preserved in FP16)
- Blue: Low-magnitude weights (quantized to INT3)
- **Perplexity (PPL)**: Consistent PPL 13.0 across panels (b) and (c)
## Cross-Panel Comparison
| Method | Precision Retained | PPL Value | Key Feature |
|----------------------|--------------------|-----------|---------------------------------|
| RTN Quantization | INT3 | 43.2 | Full matrix quantization |
| Salient Weight Pres. | FP16 (1%) | 13.0 | Activation-driven selection |
| Scaling-Aware | INT3 (scaled) | 13.0 | Magnitude-aware scaling |
## Technical Implications
1. **RTN Quantization** (Panel a):
- Balances model size reduction with accuracy preservation
- Higher PPL (43.2) indicates moderate accuracy degradation
2. **Salient Weight Preservation** (Panel b):
- Critical for hardware efficiency
- FP16 retention for 1% most impactful weights
- Lower PPL (13.0) suggests better accuracy retention
3. **Scaling-Aware Quantization** (Panel c):
- Optimizes quantization through magnitude normalization
- Maintains PPL 13.0 while enabling efficient hardware deployment