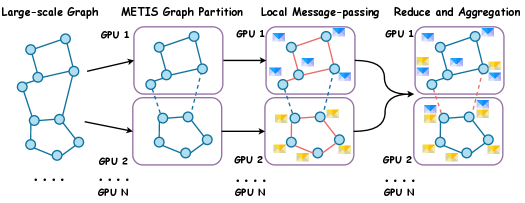
## [Diagram]: Distributed Graph Processing Pipeline
### Overview
This image is a technical diagram illustrating a four-stage pipeline for distributed graph processing across multiple GPUs. It visually explains how a large-scale graph is partitioned, processed locally, and then aggregated in a parallel computing environment.
### Components/Axes
The diagram is organized into four sequential stages, labeled at the top from left to right:
1. **Large-scale Graph**: A single, large graph structure.
2. **METIS Graph Partition**: The graph is split into two subgraphs.
3. **Local Message-passing**: Computation occurs within each partition.
4. **Reduce and Aggregation**: Results from partitions are combined.
**Key Components & Labels:**
* **Graphs/Nodes**: Represented by blue circles (nodes) connected by lines (edges).
* **GPUs**: Each processing stage (except the first) is contained within rounded rectangles labeled "GPU 1" and "GPU 2". Ellipses ("...") below each GPU box indicate the system can scale to "GPU N".
* **Data Flow**: Black arrows show the direction of data movement between stages.
* **Internal Communication**: Within the "Local Message-passing" stage, red arrows indicate communication between nodes *within* the same GPU partition. Blue dashed arrows indicate communication between nodes *across* different GPU partitions.
* **Message Icons**: Small yellow and blue envelope icons appear next to nodes in the last two stages, symbolizing data messages being passed.
* **Legend (Top Center)**: Contains Chinese text with English translations provided below.
* **Original Chinese**: `METIS 图划分` | `局部消息传递` | `规约与聚合`
* **English Translation**: `METIS Graph Partition` | `Local Message-passing` | `Reduce and Aggregation`
### Detailed Analysis
The process flows as follows:
1. **Stage 1 - Large-scale Graph**: A single, connected graph is shown on the far left. It serves as the input.
2. **Stage 2 - METIS Graph Partition**: The original graph is divided into two separate subgraphs. The partitioning is performed by the METIS algorithm (a common tool for graph partitioning). One subgraph is assigned to "GPU 1" and the other to "GPU 2". A blue dashed line connects a node in the top partition to a node in the bottom partition, indicating they were originally connected in the large-scale graph.
3. **Stage 3 - Local Message-passing**: Each GPU now processes its assigned subgraph independently.
* **Intra-GPU Communication (Red Arrows)**: Nodes within the same GPU exchange messages (yellow/blue envelopes) with their neighbors.
* **Inter-GPU Communication (Blue Dashed Arrows)**: Nodes that were split across partitions (the ones connected by the dashed line in Stage 2) must communicate across the GPU boundary. This is a critical step in distributed graph processing.
4. **Stage 4 - Reduce and Aggregation**: The final stage shows the results from each GPU's computation being aggregated. The diagram depicts this by showing the two processed subgraphs, still separate, with message icons present, implying their outputs are ready for a final collection or reduction step (not visually detailed).
### Key Observations
* **Scalability**: The "..." and "GPU N" notation explicitly indicates the architecture is designed for scalability beyond the two GPUs shown.
* **Communication Pattern**: The diagram clearly distinguishes between fast, local communication within a GPU (red arrows) and slower, cross-partition communication between GPUs (blue dashed arrows). This is a fundamental challenge in distributed systems.
* **Partitioning Role**: The METIS stage is crucial for minimizing the number of edges cut between partitions (represented by the single dashed line), which in turn minimizes the expensive inter-GPU communication in the next stage.
### Interpretation
This diagram explains a standard methodology for scaling graph algorithms to handle massive datasets that cannot fit in the memory of a single device. The core idea is **divide-and-conquer**:
1. **Partition**: Break the problem (graph) into smaller, manageable chunks (subgraphs) using an algorithm like METIS that aims to keep strongly connected nodes together.
2. **Parallel Process**: Assign each chunk to a separate processor (GPU) for local computation. This is the "embarrassingly parallel" part.
3. **Manage Communication**: Handle the necessary communication between processors for nodes that were split during partitioning. The efficiency of the entire system heavily depends on minimizing this step.
4. **Aggregate**: Combine the partial results from all processors to form the final answer.
The visual emphasis on the communication arrows (red vs. blue dashed) highlights that the performance bottleneck in such systems is often not the computation itself, but the data transfer between nodes. The diagram serves as a conceptual blueprint for implementing efficient, distributed graph processing frameworks.