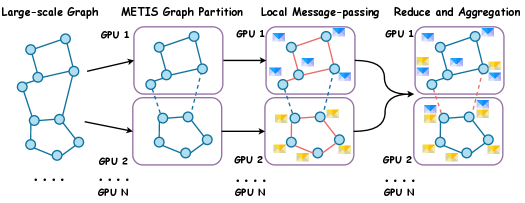
# Technical Document Extraction: Distributed Graph Processing Workflow
## Overview
The image depicts a multi-stage distributed graph processing workflow across N GPUs. The process involves graph partitioning, local computation, and aggregation phases. Key components include graph nodes, message-passing patterns, and data aggregation mechanisms.
## Key Components & Flow
1. **Large-scale Graph**
- Initial undirected graph structure with interconnected nodes (blue circles)
- Represented as a single global graph spanning all GPUs
2. **METIS Graph Partition**
- Graph divided into N subgraphs using METIS partitioning algorithm
- Each GPU (GPU 1 to GPU N) receives a distinct subgraph
- Visual representation shows partitioned subgraphs with dashed boundary lines
3. **Local Message-passing**
- GPU-local computation phase with message exchange between nodes
- Message types differentiated by color:
- **Blue arrows**: Standard messages
- **Red arrows**: Priority/urgent messages
- Each GPU processes its subgraph with internal communication
4. **Reduce and Aggregation**
- Final phase combining results across GPUs
- Data aggregation represented by:
- **Yellow envelopes**: Intermediate results
- **Red dashed lines**: Cross-GPU communication paths
- Final aggregated graph structure shown with combined node/message patterns
## Legend & Spatial Grounding
- **Legend Location**: Bottom-right quadrant
- **Color Coding**:
- Blue: Graph nodes (consistent across all stages)
- Red: Message-passing channels (local and cross-GPU)
- Yellow: Aggregated data packages
- **Spatial Verification**:
- All GPU sections maintain consistent color coding
- Message types retain color consistency between local and cross-GPU phases
## Process Flow Analysis
1. **Partitioning Phase**
- Global graph (x=0) → METIS partitioning (x=1)
- Spatial progression: Left-to-right horizontal flow
2. **Computation Phase**
- Partitioned subgraphs (x=1) → Local message-passing (x=2)
- GPU-specific processing with internal communication
3. **Aggregation Phase**
- Local results (x=2) → Global aggregation (x=3)
- Cross-GPU communication via red dashed lines
## Technical Implementation Details
- **Parallel Architecture**:
- N GPUs process N subgraphs in parallel
- Memory locality maintained through METIS partitioning
- **Communication Pattern**:
- Local: Red/blue arrows within GPU subgraphs
- Global: Red dashed lines between GPU partitions
- **Data Flow**:
- Initial graph → Partitioned subgraphs → Processed subgraphs → Aggregated results
## Limitations
- No numerical data points or quantitative metrics present
- Focus on architectural workflow rather than performance metrics
- Assumes perfect partitioning and communication efficiency
## Conclusion
The diagram illustrates a standard distributed graph processing pipeline using METIS partitioning and multi-GPU computation. The workflow emphasizes locality-aware computation followed by cross-node aggregation, with clear visual differentiation between computation phases and communication patterns.