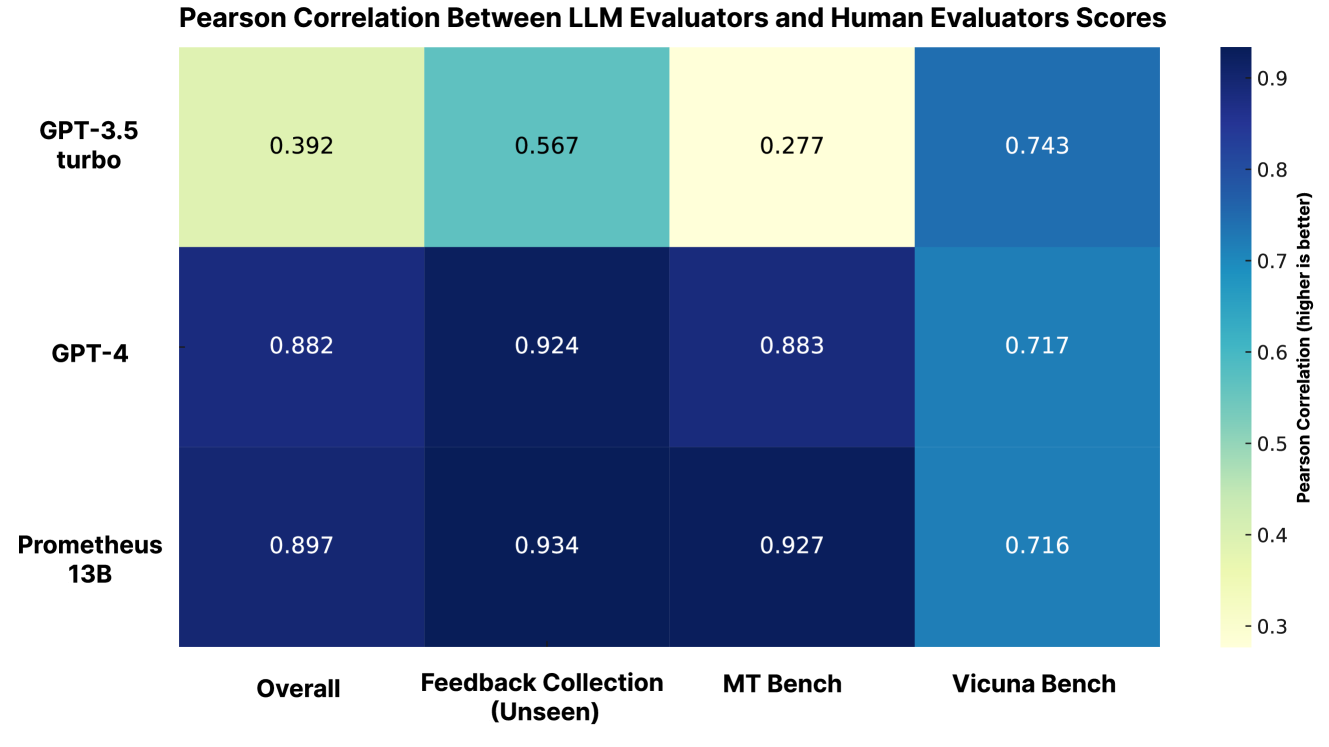
# Technical Document Extraction: Pearson Correlation Heatmap
## Image Description
The image is a **heatmap** visualizing Pearson correlation coefficients between Large Language Model (LLM) evaluators and human evaluators' scores. The chart uses a **color gradient** (from light green to dark blue) to represent correlation strength, with darker blues indicating higher correlation (closer to 1.0).
---
### Key Components
1. **Title**:
`"Pearson Correlation Between LLM Evaluators and Human Evaluators Scores"`
2. **Axes**:
- **X-axis (Columns)**:
Categories:
- `Overall`
- `Feedback Collection (Unseen)`
- `MT Bench`
- `Vicuna Bench`
- **Y-axis (Rows)**:
Models:
- `GPT-3.5 turbo`
- `GPT-4`
- `Prometheus 13B`
3. **Legend**:
- Located on the **right edge** of the chart.
- **Color Scale**:
- Light green (`~0.3`) to dark blue (`~0.9`).
- Label: `"Pearson Correlation (higher is better)"`
4. **Data Table**:
Reconstructed from the heatmap cells (values rounded to 3 decimal places):
| Model | Overall | Feedback Collection (Unseen) | MT Bench | Vicuna Bench |
|------------------|---------|------------------------------|----------|--------------|
| GPT-3.5 turbo | 0.392 | 0.567 | 0.277 | 0.743 |
| GPT-4 | 0.882 | 0.924 | 0.883 | 0.717 |
| Prometheus 13B | 0.897 | 0.934 | 0.927 | 0.716 |
---
### Spatial Grounding
- **Legend Position**: Right edge of the chart (x = 1.0, y = 0.5 ± 0.5 height).
- **Color Matching**:
- Light green cells (e.g., GPT-3.5 turbo's `MT Bench`) align with the lower end of the legend.
- Dark blue cells (e.g., Prometheus 13B's `Feedback Collection`) align with the upper end.
---
### Trend Verification
1. **GPT-3.5 turbo**:
- Weakest correlations overall (light green to medium blue).
- Strongest in `Vicuna Bench` (0.743).
2. **GPT-4**:
- Strong correlations (dark blue to near-black).
- Highest in `Feedback Collection` (0.924).
3. **Prometheus 13B**:
- Strongest correlations overall (darkest blue).
- Peak in `Feedback Collection` (0.934) and `MT Bench` (0.927).
---
### Notes
- **No additional text or diagrams** are present.
- **No non-English content** detected.
- **No legends for lines or colors beyond the Pearson scale**.
This heatmap highlights that **Prometheus 13B** and **GPT-4** show the strongest alignment with human evaluators across benchmarks, while **GPT-3.5 turbo** exhibits weaker correlations, particularly in `MT Bench`.