## Line Chart: L0 over Training Steps
### Overview
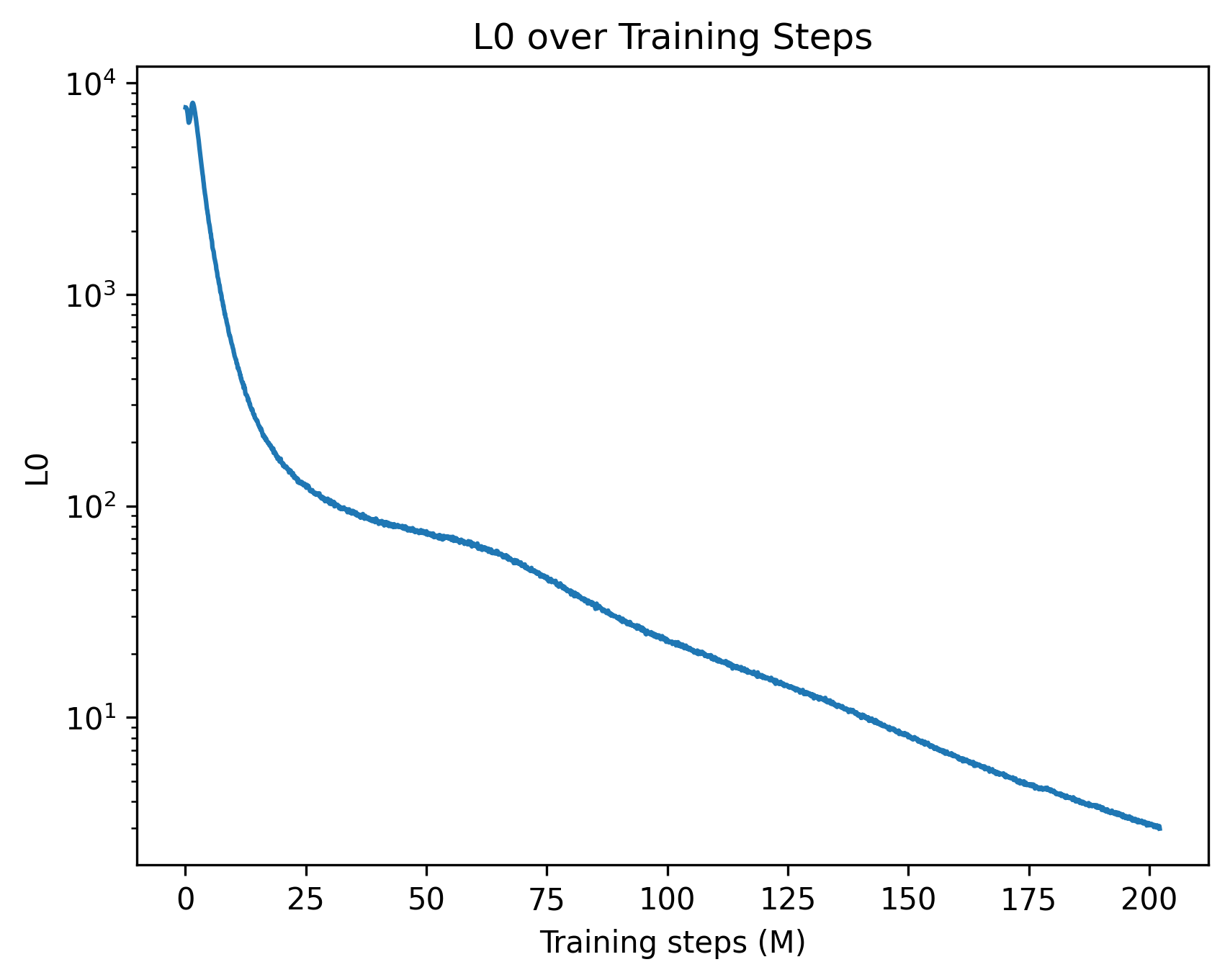
The image is a line chart displaying the relationship between "L0" (on a logarithmic scale) and "Training steps (M)" on a linear scale. The chart shows a decreasing trend of L0 as the number of training steps increases.
### Components/Axes
* **Title:** L0 over Training Steps
* **X-axis:**
* Label: Training steps (M)
* Scale: Linear
* Markers: 0, 25, 50, 75, 100, 125, 150, 175, 200
* **Y-axis:**
* Label: L0
* Scale: Logarithmic (base 10)
* Markers: 10<sup>1</sup>, 10<sup>2</sup>, 10<sup>3</sup>, 10<sup>4</sup>
### Detailed Analysis
* **Data Series:** A single blue line represents the data.
* **Trend:** The line shows a steep decrease initially, followed by a gradual decline as the number of training steps increases.
* **Values:**
* At 0 Training steps, L0 is approximately 8000 - 9000.
* At 25 Training steps, L0 is approximately 90 - 100.
* At 50 Training steps, L0 is approximately 70 - 80.
* At 75 Training steps, L0 is approximately 30 - 40.
* At 100 Training steps, L0 is approximately 20 - 30.
* At 125 Training steps, L0 is approximately 15 - 20.
* At 150 Training steps, L0 is approximately 10 - 15.
* At 175 Training steps, L0 is approximately 7 - 10.
* At 200 Training steps, L0 is approximately 5 - 7.
### Key Observations
* The most significant decrease in L0 occurs within the first 25 training steps.
* The rate of decrease slows down considerably after 50 training steps.
* The y-axis is on a log scale, which means that equal distances represent multiplicative changes in L0.
### Interpretation
The chart illustrates the learning process of a model, where L0 likely represents a loss function or error metric. The decreasing trend indicates that the model is learning and improving as it is trained over more steps. The initial rapid decrease suggests a quick initial learning phase, while the subsequent gradual decline indicates diminishing returns as the model approaches convergence. The logarithmic scale emphasizes the relative changes in L0, highlighting the significant reduction in error during the early stages of training.