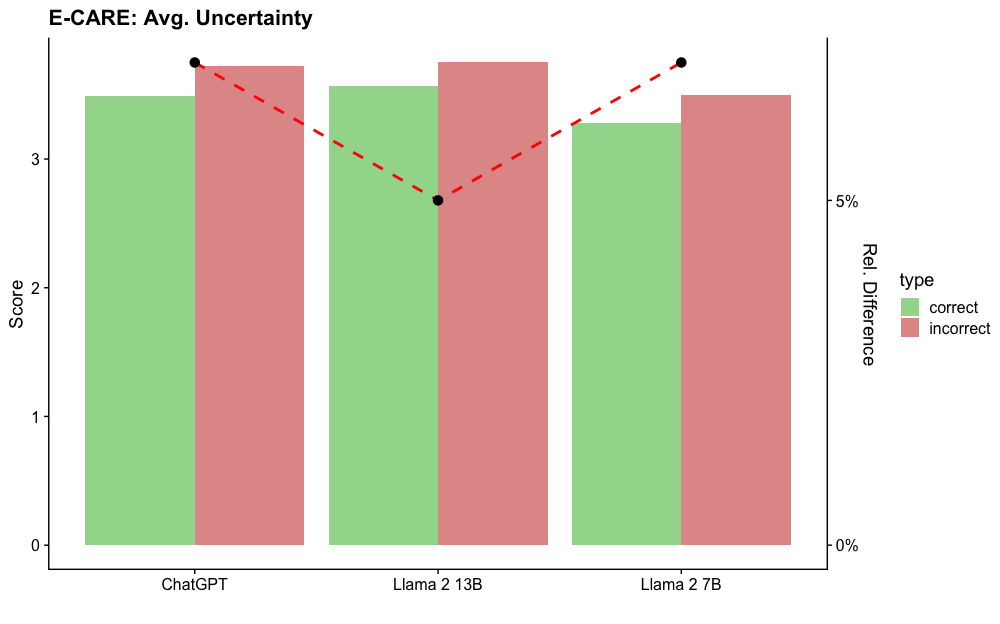
## Bar Chart: E-CARE: Avg. Uncertainty
### Overview
The image is a bar chart comparing the average uncertainty scores of three language models (ChatGPT, Llama 2 13B, and Llama 2 7B) on the E-CARE dataset. The chart displays scores for both "correct" and "incorrect" response types, represented by green and red bars, respectively. A secondary y-axis shows the relative difference between the "correct" and "incorrect" scores, plotted as a red dashed line with black circular markers.
### Components/Axes
* **Title:** E-CARE: Avg. Uncertainty
* **X-axis:** Language Models (ChatGPT, Llama 2 13B, Llama 2 7B)
* **Primary Y-axis:** Score, ranging from 0 to 3, with tick marks at 0, 1, 2, and 3.
* **Secondary Y-axis:** Rel. Difference, ranging from 0% to 5%, with tick marks at 0% and 5%.
* **Legend:** Located on the right side of the chart, indicating "correct" responses with a green bar and "incorrect" responses with a red bar.
### Detailed Analysis
* **ChatGPT:**
* Correct: The green bar extends to approximately 3.4.
* Incorrect: The red bar extends to approximately 3.6.
* **Llama 2 13B:**
* Correct: The green bar extends to approximately 3.4.
* Incorrect: The red bar extends to approximately 3.8.
* **Llama 2 7B:**
* Correct: The green bar extends to approximately 3.2.
* Incorrect: The red bar extends to approximately 3.5.
* **Relative Difference (Red Dashed Line):**
* ChatGPT: Starts at approximately 4.5%.
* Llama 2 13B: Drops to approximately 2.5%.
* Llama 2 7B: Rises to approximately 4.7%.
### Key Observations
* For all three language models, the "incorrect" scores are higher than the "correct" scores, indicating higher uncertainty for incorrect responses.
* Llama 2 13B has the highest "incorrect" score and the lowest relative difference.
* ChatGPT and Llama 2 7B have similar relative differences, but ChatGPT has slightly lower "incorrect" score.
### Interpretation
The chart suggests that all three language models exhibit higher uncertainty when generating incorrect responses compared to correct ones. The relative difference in uncertainty between correct and incorrect responses varies across the models, with Llama 2 13B showing the smallest difference. This could indicate that Llama 2 13B's uncertainty is less indicative of its correctness compared to the other two models. The data implies that uncertainty scores could potentially be used as a metric to assess the reliability of these language models, with lower uncertainty generally correlating with more accurate responses.