\n
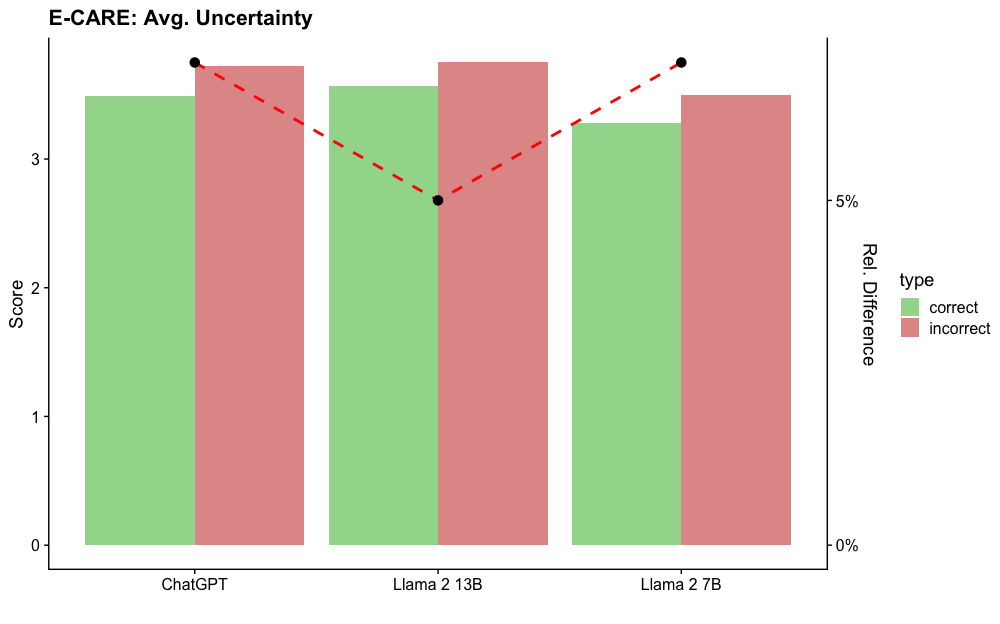
## Bar Chart: E-CARE Avg. Uncertainty
### Overview
This bar chart compares the average uncertainty scores for three different language models: ChatGPT, Llama 2 13B, and Llama 2 7B. The chart uses paired bars to represent "correct" and "incorrect" responses, with a dashed line connecting the average scores for each model. The y-axis represents the score, while the right y-axis represents the relative difference.
### Components/Axes
* **Title:** E-CARE: Avg. Uncertainty
* **X-axis:** Model Name (ChatGPT, Llama 2 13B, Llama 2 7B)
* **Y-axis (left):** Score (Scale from 0 to 4, with increments of 1)
* **Y-axis (right):** Rel. Difference (Scale from 0% to 5%, with increments of 1%)
* **Legend (top-right):**
* Type: correct (Green)
* Type: incorrect (Red)
### Detailed Analysis
The chart consists of three groups of paired bars, one for each model. Each group contains a green bar representing the "correct" responses and a red bar representing the "incorrect" responses. A dashed red line connects the top of the green and red bars for each model, representing the average uncertainty score.
**ChatGPT:**
* Correct: Approximately 3.6 (Green bar)
* Incorrect: Approximately 3.2 (Red bar)
* Average (dashed line): Approximately 3.4
**Llama 2 13B:**
* Correct: Approximately 3.1 (Green bar)
* Incorrect: Approximately 3.7 (Red bar)
* Average (dashed line): Approximately 3.4
**Llama 2 7B:**
* Correct: Approximately 3.5 (Green bar)
* Incorrect: Approximately 3.8 (Red bar)
* Average (dashed line): Approximately 3.65
The relative difference scale on the right y-axis is not directly used to extract numerical values from the chart, but it indicates the scale for the difference between the correct and incorrect scores.
### Key Observations
* ChatGPT has the highest average score for correct responses and a relatively lower score for incorrect responses.
* Llama 2 13B has the lowest average score for correct responses and the highest score for incorrect responses.
* The average uncertainty score is approximately the same for ChatGPT and Llama 2 13B (around 3.4).
* Llama 2 7B has a higher average uncertainty score than both ChatGPT and Llama 2 13B.
* The dashed line connecting the bars shows a slight upward trend from ChatGPT to Llama 2 7B.
### Interpretation
The chart suggests that ChatGPT performs better on the E-CARE task in terms of lower uncertainty for correct responses, while Llama 2 13B exhibits higher uncertainty, particularly for incorrect responses. Llama 2 7B shows a slightly higher overall uncertainty compared to ChatGPT. The consistent average score of approximately 3.4 for ChatGPT and Llama 2 13B could indicate a similar level of confidence in their responses, despite differences in the correctness of those responses. The upward trend in the dashed line suggests that as the model size decreases (from 13B to 7B), the average uncertainty score increases. This could be due to the smaller model having less capacity to accurately assess its own confidence. The relative difference scale, while present, doesn't provide specific insights without knowing the exact values for each bar. The chart highlights the trade-off between model size and uncertainty in the context of the E-CARE task.