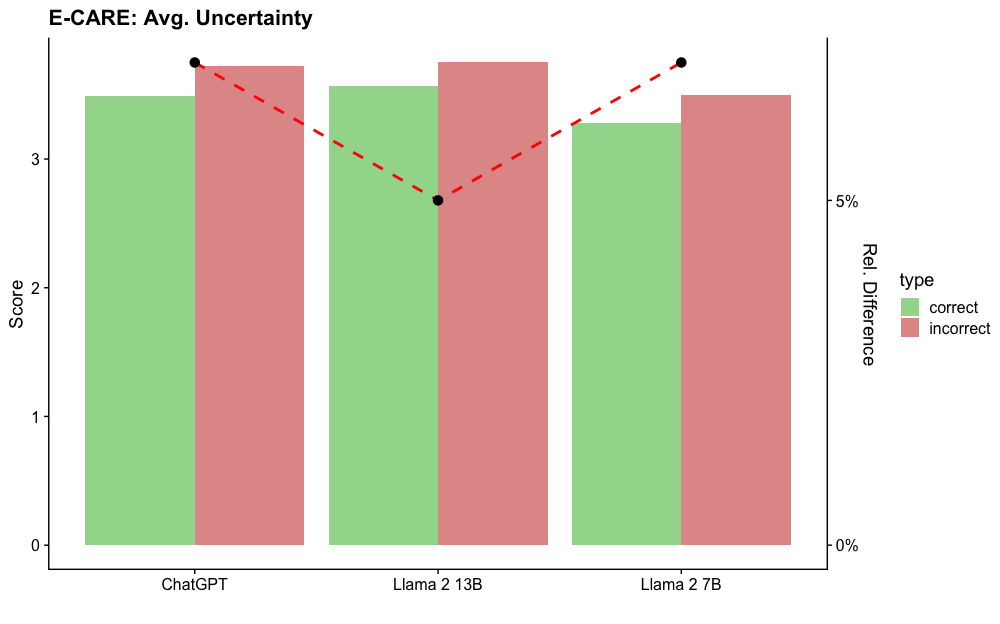
## Bar Chart: E-CARE: Avg. Uncertainty
### Overview
The chart compares the average uncertainty scores of three language models (ChatGPT, Llama 2 13B, Llama 2 7B) across two categories: "correct" and "incorrect" answers. Uncertainty scores range from 0 to 4, with higher values indicating greater uncertainty. A red dashed line connects the "incorrect" bars across models, highlighting trends in uncertainty for incorrect responses.
---
### Components/Axes
- **X-axis**: Model names (ChatGPT, Llama 2 13B, Llama 2 7B).
- **Y-axis (left)**: Score (0–4), labeled "Score."
- **Legend (right)**:
- Green = "correct" answers.
- Red = "incorrect" answers.
- **Dashed Line**: Red, connects "incorrect" bars across models.
---
### Detailed Analysis
1. **ChatGPT**:
- Correct: ~3.5 (green bar).
- Incorrect: ~3.8 (red bar).
2. **Llama 2 13B**:
- Correct: ~3.6 (green bar).
- Incorrect: ~2.7 (red bar, lowest among "incorrect" scores).
3. **Llama 2 7B**:
- Correct: ~3.3 (green bar).
- Incorrect: ~3.6 (red bar).
---
### Key Observations
- **Higher Uncertainty for Incorrect Answers**: All models show higher uncertainty scores for incorrect answers compared to correct ones (e.g., ChatGPT: 3.8 vs. 3.5).
- **Llama 2 13B Anomaly**: Its "incorrect" score (~2.7) is significantly lower than the other models, creating a dip in the red dashed line.
- **Consistency in Correct Answers**: Correct scores are relatively stable across models (3.3–3.6).
---
### Interpretation
The data suggests that language models exhibit greater uncertainty when generating incorrect answers, aligning with expectations. However, Llama 2 13B’s lower uncertainty for incorrect responses (~2.7) is anomalous. This could indicate:
- **Better Calibration**: Llama 2 13B may be more confident in its errors, possibly due to training data or architecture differences.
- **Error Pattern**: The model might produce fewer "high-uncertainty" errors, suggesting a different failure mode (e.g., overconfidence in incorrect outputs).
The red dashed line emphasizes the divergence in uncertainty trends, particularly for Llama 2 13B, warranting further investigation into its error behavior.