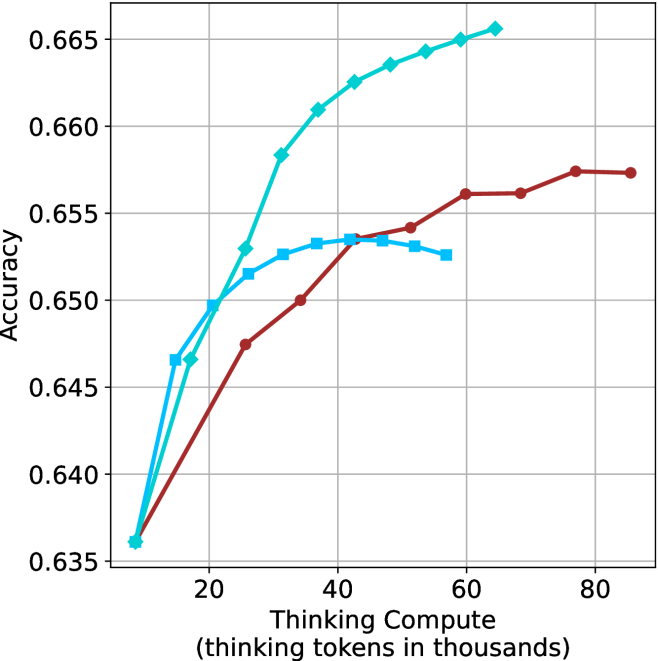
## Line Graph: Model Accuracy vs. Thinking Compute
### Overview
The image is a line graph comparing the accuracy of three AI models as a function of "Thinking Compute" (measured in thousands of thinking tokens). The graph shows three data series: "Thinking Compute" (cyan), "Thinking Compute + Prompt" (blue), and "Thinking Compute + Prompt + Chain-of-Thought" (red). The y-axis represents accuracy (ranging from 0.635 to 0.665), while the x-axis represents thinking compute in thousands of tokens (ranging from 20 to 80k).
### Components/Axes
- **X-axis**: "Thinking Compute (thinking tokens in thousands)" with values at 20, 40, 60, and 80k.
- **Y-axis**: "Accuracy" with values from 0.635 to 0.665.
- **Legend**: Located on the right side of the graph, with three entries:
- **Cyan**: "Thinking Compute"
- **Blue**: "Thinking Compute + Prompt"
- **Red**: "Thinking Compute + Prompt + Chain-of-Thought"
### Detailed Analysis
1. **Thinking Compute (Cyan Line)**:
- Starts at **0.635** at 20k tokens.
- Rises sharply to **0.645** at 40k tokens.
- Continues increasing steadily, reaching **0.665** at 80k tokens.
- **Trend**: Consistent upward slope with no plateaus.
2. **Thinking Compute + Prompt (Blue Line)**:
- Starts at **0.645** at 20k tokens.
- Peaks at **0.654** around 40k tokens.
- Dips slightly to **0.652** at 60k tokens.
- **Trend**: Initial rise followed by a plateau and minor decline.
3. **Thinking Compute + Prompt + Chain-of-Thought (Red Line)**:
- Starts at **0.635** at 20k tokens.
- Rises gradually to **0.655** at 80k tokens.
- **Trend**: Steady upward slope with no significant fluctuations.
### Key Observations
- The **cyan line** ("Thinking Compute") achieves the highest accuracy across all compute levels, particularly at higher token counts (e.g., 0.665 at 80k).
- The **blue line** ("Thinking Compute + Prompt") shows a peak at 40k tokens but declines slightly at 60k, suggesting potential overfitting or diminishing returns.
- The **red line** ("Thinking Compute + Prompt + Chain-of-Thought") has the lowest accuracy but demonstrates a consistent upward trend, indicating that Chain-of-Thought (CoT) improves performance with increased compute.
### Interpretation
The data suggests that **higher thinking compute** (tokens) correlates with **higher accuracy** for all models. However, the addition of **prompts** (blue line) introduces variability: while it initially improves performance, it may lead to overfitting or inefficiencies at higher compute levels. The **Chain-of-Thought** (red line) model shows the most stable improvement, implying that CoT enhances reasoning capabilities when paired with sufficient compute. The cyan line’s dominance highlights the critical role of raw compute in achieving optimal accuracy, while the blue line’s dip underscores the risks of over-reliance on prompts without adequate compute. This analysis emphasizes the trade-offs between model complexity, compute resources, and performance gains.