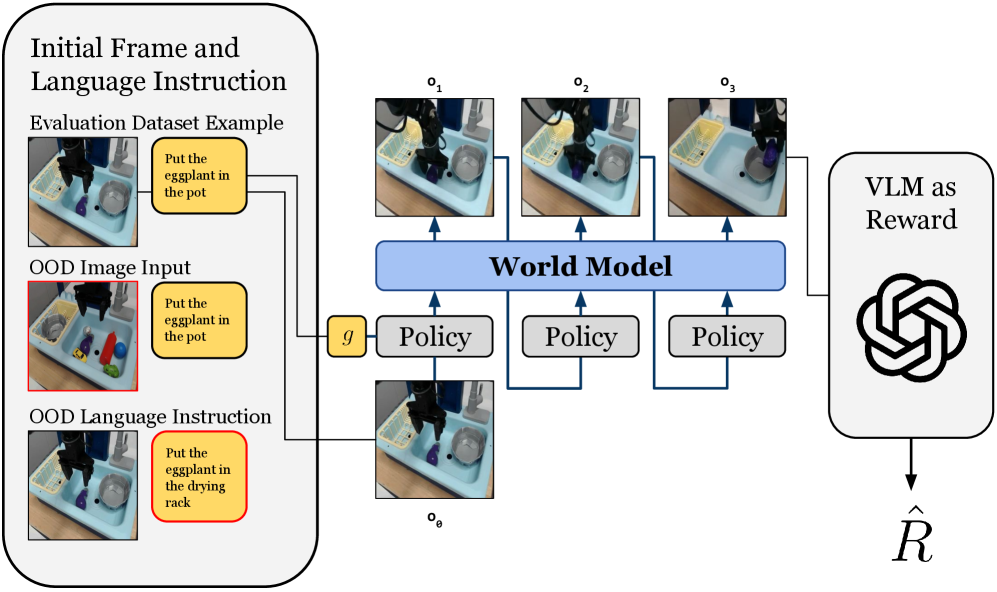
## Diagram: Robotic Task Execution with Language Instruction
### Overview
The image depicts a diagram illustrating a robotic task execution system guided by language instructions, incorporating a world model and a Vision Language Model (VLM) for reward assessment. The system processes initial frames and language instructions, uses a policy to interact with the environment, and evaluates the outcome using a VLM.
### Components/Axes
* **Initial Frame and Language Instruction (Top-Left)**: This section shows an example from the evaluation dataset. It includes an image of a scene and a corresponding language instruction.
* **Evaluation Dataset Example**: Contains an image of a robot arm above a sink with various objects, and a text box stating "Put the eggplant in the pot".
* **OOD Image Input**: Shows a similar scene with different objects and a red border, with the instruction "Put the eggplant in the pot". OOD stands for Out-Of-Distribution.
* **OOD Language Instruction**: Shows the same scene as the OOD Image Input, but with the instruction "Put the eggplant in the drying rack" and a red border.
* **World Model (Center)**: A blue rectangular box labeled "World Model" represents the system's internal representation of the environment.
* **Policy (Center)**: Three gray rectangular boxes labeled "Policy" represent the decision-making component that determines the robot's actions.
* **Observations (Top-Center)**: Three images labeled o1, o2, and o3 show the robot's observations at different time steps.
* **Initial Observation (Bottom-Center)**: An image labeled o0 shows the initial observation.
* **VLM as Reward (Right)**: A rounded rectangle labeled "VLM as Reward" contains a stylized image resembling the OpenAI logo. It outputs a reward signal denoted as R-hat.
* **Connections**: Blue arrows indicate the flow of information between components.
### Detailed Analysis
* **Initial Frame and Language Instruction**:
* The "Evaluation Dataset Example" shows a typical input with a clear instruction.
* The "OOD Image Input" introduces a scenario where the visual input is different from the training data.
* The "OOD Language Instruction" introduces a scenario where the language instruction is different from the training data.
* **World Model**: The World Model receives input from the initial state (g) and the observations from the environment.
* **Policy**: The Policy modules receive input from the World Model and generate actions that affect the environment.
* **Observations**: The observations (o1, o2, o3) represent the robot's perception of the environment at different time steps.
* **VLM as Reward**: The VLM evaluates the outcome of the robot's actions and provides a reward signal.
### Key Observations
* The diagram highlights the use of a World Model to integrate visual and linguistic information.
* The system uses a Policy to make decisions based on the World Model.
* The VLM is used to provide a reward signal, enabling the system to learn from its actions.
* The OOD examples demonstrate the system's ability to handle novel situations.
### Interpretation
The diagram illustrates a robotic task execution system that leverages a World Model and a VLM to perform tasks based on language instructions. The system is designed to handle both familiar and novel situations, as demonstrated by the OOD examples. The VLM-based reward system enables the robot to learn from its actions and improve its performance over time. The diagram suggests a closed-loop control system where the robot continuously interacts with the environment, updates its internal representation, and adjusts its actions based on the reward signal. The use of a VLM as a reward function is a key aspect of this system, as it allows the robot to learn from unstructured visual and linguistic data.