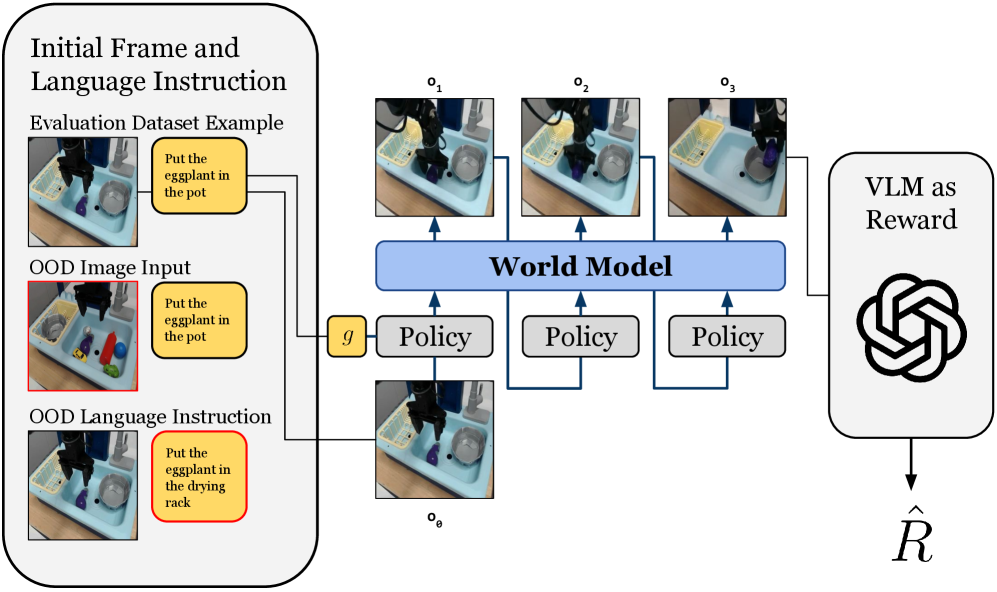
## System Architecture Diagram: Reinforcement Learning with World Model and VLM Reward
### Overview
This image is a technical system architecture diagram illustrating a reinforcement learning or robotic control pipeline. It depicts a process that starts with visual and language instructions, uses a world model and policy to generate action sequences, and finally employs a Vision-Language Model (VLM) to compute a reward signal. The diagram is structured into three main vertical sections: Input, Processing, and Reward Calculation.
### Components/Axes
The diagram is organized into distinct regions with labeled components and directional arrows indicating data flow.
**1. Left Panel: Initial Frame and Language Instruction (Input Region)**
* **Header:** "Initial Frame and Language Instruction"
* **Three Input Examples:**
* **Top Example:** Labeled "Evaluation Dataset Example". Contains an image of a robotic arm over a sink with objects and a yellow instruction box with the text: "Put the eggplant in the pot".
* **Middle Example:** Labeled "OOD Image Input" (OOD likely means Out-Of-Distribution). The image shows a different scene with more colorful objects. The instruction box is identical: "Put the eggplant in the pot".
* **Bottom Example:** Labeled "OOD Language Instruction". The image is similar to the top example, but the instruction box has a red border and different text: "Put the eggplant in the drying rack".
* **Flow:** Arrows from all three examples converge and point to a small yellow box labeled "g" in the central processing region.
**2. Central Processing Region**
* **Input Node:** A small yellow box labeled "g". It receives input from the left panel.
* **Initial Observation:** An image labeled "o₀" (o subscript 0) is shown below the "g" box. It depicts the initial state of the robotic workspace.
* **Policy Blocks:** Three identical gray rectangular blocks labeled "Policy". They are arranged horizontally.
* **World Model Block:** A large, light blue horizontal bar labeled "World Model" in bold text. It spans above the three Policy blocks.
* **Observation Sequence:** Three images labeled "o₁", "o₂", and "o₃" (o subscripts 1, 2, 3) are positioned above the World Model bar. They show sequential states of the robotic arm performing the task.
* **Flow Arrows:**
* An arrow goes from "g" to the first "Policy" block.
* Arrows connect the "Policy" blocks to the "World Model" bar from below.
* Arrows point upward from the "World Model" bar to each of the observation images ("o₁", "o₂", "o₃").
* A final arrow leads from the last observation ("o₃") to the right panel.
**3. Right Panel: Reward Calculation**
* **Header:** "VLM as Reward"
* **Logo:** A black, stylized, interlocking circular logo (resembling the OpenAI logo) is centered in this panel.
* **Output Symbol:** An arrow points downward from the logo to a mathematical symbol: "R̂" (R with a circumflex/hat), representing the estimated or predicted reward.
### Detailed Analysis
The diagram details a sequential decision-making process:
1. **Input Stage:** The system takes an initial visual observation (`o₀`) and a language instruction (encapsulated by `g`). The examples show the system is being tested on both in-distribution ("Evaluation Dataset") and out-of-distribution (OOD) scenarios, varying either the image context or the language command.
2. **Action & Prediction Stage:** The policy network, conditioned on the input `g`, generates actions. These actions and the current state are fed into a "World Model." The World Model's role is to predict future states of the environment, generating the sequence of predicted observations: `o₁`, `o₂`, `o₃`.
3. **Reward Assignment Stage:** The final predicted state (`o₃`) is passed to a "VLM as Reward" module. This module, represented by a large language model logo, evaluates how well the final state fulfills the original instruction and outputs a scalar reward value, `R̂`.
### Key Observations
* **OOD Testing:** The diagram explicitly highlights testing for robustness by including "OOD Image Input" and "OOD Language Instruction" as separate cases, indicating the system's generalization capability is a key focus.
* **World Model Centrality:** The "World Model" is the largest and most central component, suggesting it is the core innovation or focus of this architecture. It acts as a simulator or predictor of future states.
* **VLM as a Reward Function:** Using a Vision-Language Model (VLM) to compute reward (`R̂`) is a notable design choice. It implies the reward is not from a pre-defined metric but from a model that can understand both the visual outcome and the language goal.
* **Sequential Predictions:** The output of the World Model is a sequence of frames (`o₁` to `o₃`), not just a final state, which may allow for more granular reward assessment or planning.
### Interpretation
This diagram represents a **model-based reinforcement learning framework for language-conditioned robotic tasks**. The key investigative insight is the integration of a **World Model** for planning or simulation with a **Vision-Language Model (VLM)** as a flexible, semantic reward function.
* **What it demonstrates:** The system aims to learn policies that can follow natural language instructions in physical environments. By using a world model, it can "imagine" the consequences of its actions before executing them. The VLM reward allows the system to be trained or evaluated based on high-level, human-understandable goals ("put X in Y") rather than low-level coordinates.
* **Relationships:** The policy and world model are tightly coupled in a planning loop. The VLM sits outside this loop as an evaluator. The OOD examples stress that the entire pipeline—from perception (images) to understanding (language) to action (policy)—must be robust.
* **Notable Implications:** This architecture could enable robots to generalize better to new objects and instructions. The use of a VLM as a reward also points toward **reinforcement learning from human feedback (RLHF)** or **goal-conditioned RL** paradigms, where the reward signal is derived from a model that encapsulates human preferences or task semantics. The hat on the R (`R̂`) signifies it is an estimate, acknowledging the potential noise or imperfection in the VLM's judgment.