\n
## Bar Chart: Contextual Nuclear Knowledge
### Overview
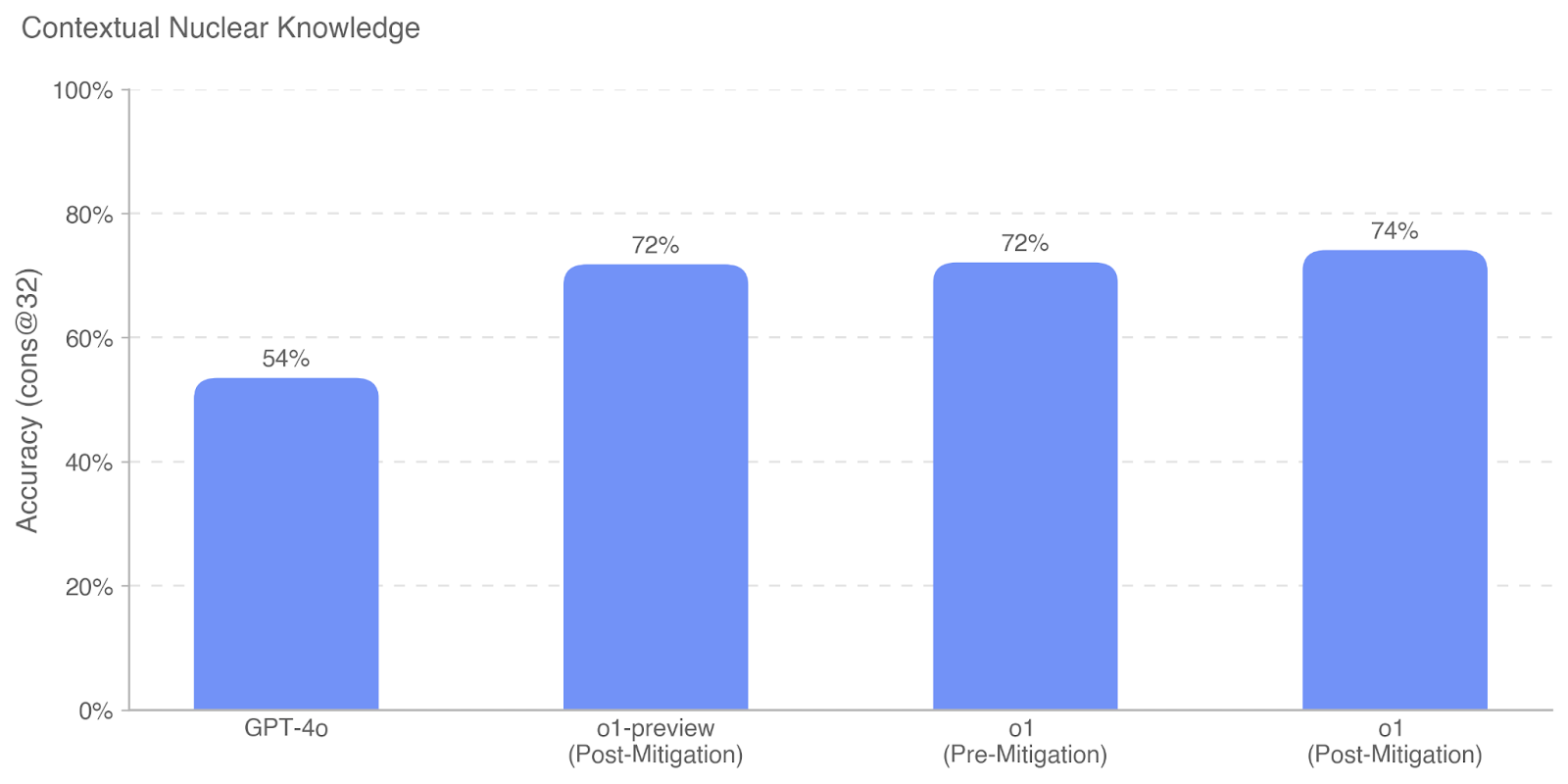
This bar chart compares the accuracy of GPT-4o and different versions of "o1" (likely a model or system) on "Contextual Nuclear Knowledge". Accuracy is measured as "cons@32", and the chart shows the impact of "Mitigation" on performance.
### Components/Axes
* **Title:** Contextual Nuclear Knowledge (top-center)
* **X-axis:** Model/Version (bottom-center)
* Categories: GPT-4o, o1-preview (Post-Mitigation), o1 (Pre-Mitigation), o1 (Post-Mitigation)
* **Y-axis:** Accuracy (cons@32) (left-center)
* Scale: 0% to 100%
* Markers: 0%, 20%, 40%, 60%, 80%, 100%
* **Bars:** Light blue, representing accuracy values for each category.
### Detailed Analysis
The chart displays four bars, each representing the accuracy of a different model or version.
* **GPT-4o:** The bar for GPT-4o reaches approximately 54% accuracy.
* **o1-preview (Post-Mitigation):** The bar for o1-preview (Post-Mitigation) reaches approximately 72% accuracy.
* **o1 (Pre-Mitigation):** The bar for o1 (Pre-Mitigation) reaches approximately 72% accuracy.
* **o1 (Post-Mitigation):** The bar for o1 (Post-Mitigation) reaches approximately 74% accuracy.
### Key Observations
* GPT-4o has significantly lower accuracy compared to the "o1" versions.
* The "o1" versions show similar accuracy whether pre- or post-mitigation, with a slight increase in accuracy after mitigation.
* The "o1-preview" version performs similarly to the "o1" version before mitigation.
### Interpretation
The data suggests that the "o1" models, and particularly the "o1-preview" model, demonstrate a substantially better understanding of "Contextual Nuclear Knowledge" than GPT-4o. The mitigation process appears to have a minor positive effect on the "o1" model's accuracy, but the difference is small. The consistent performance of "o1" before and after mitigation suggests that the mitigation strategy may not be the primary driver of the observed accuracy. The fact that "o1-preview" performs similarly to "o1" pre-mitigation could indicate that the "preview" version is an earlier iteration of the "o1" model. The metric "cons@32" likely refers to the number of times the correct answer appears within the top 32 predictions. This chart is a comparative performance analysis, highlighting the strengths of the "o1" models in this specific knowledge domain.