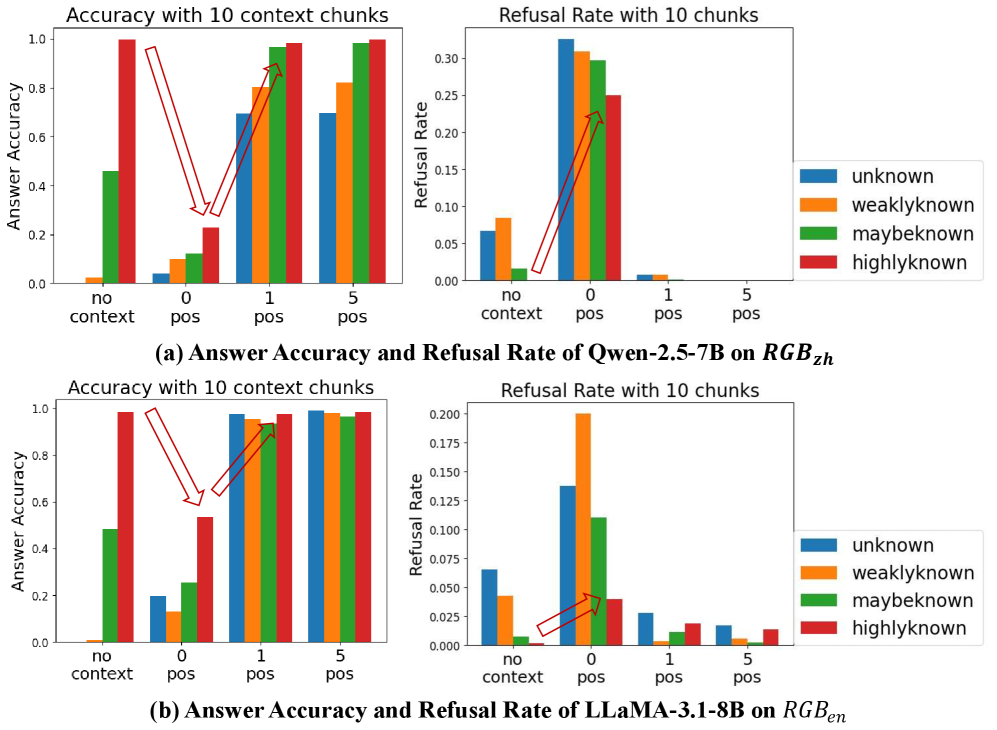
## Bar Charts: Answer Accuracy and Refusal Rate with 10 Context Chunks
### Overview
The image contains four bar charts arranged in a 2x2 grid. The top row displays the answer accuracy and refusal rate for the Qwen-2.5-7B model on RGBzh, while the bottom row shows the same metrics for the LLaMA-3.1-8B model on RGBen. Each chart compares performance across different context settings: "no context", "0 pos", "1 pos", and "5 pos". The bars are color-coded to represent different levels of knowledge: "unknown" (blue), "weaklyknown" (orange), "maybeknown" (green), and "highlyknown" (red).
### Components/Axes
**General Chart Elements:**
* **Titles:** Each chart has a title indicating the metric (Accuracy or Refusal Rate) and the number of context chunks (10). The overall figure has titles indicating the model and dataset used.
* **X-axis:** The x-axis is consistent across all charts, representing the context settings: "no context", "0 pos", "1 pos", and "5 pos".
* **Y-axis:** The y-axis on the left charts represents "Answer Accuracy", ranging from 0.0 to 1.0. The y-axis on the right charts represents "Refusal Rate", ranging from 0.0 to 0.3 for the top chart and 0.0 to 0.2 for the bottom chart.
* **Legend:** Located on the right side of the image, the legend maps colors to knowledge levels: blue for "unknown", orange for "weaklyknown", green for "maybeknown", and red for "highlyknown".
**Specific Chart Details:**
* **Top-Left Chart:** "Accuracy with 10 context chunks" for Qwen-2.5-7B on RGBzh. Y-axis: "Answer Accuracy" (0.0 to 1.0).
* **Top-Right Chart:** "Refusal Rate with 10 chunks" for Qwen-2.5-7B on RGBzh. Y-axis: "Refusal Rate" (0.0 to 0.3).
* **Bottom-Left Chart:** "Accuracy with 10 context chunks" for LLaMA-3.1-8B on RGBen. Y-axis: "Answer Accuracy" (0.0 to 1.0).
* **Bottom-Right Chart:** "Refusal Rate with 10 chunks" for LLaMA-3.1-8B on RGBen. Y-axis: "Refusal Rate" (0.0 to 0.2).
### Detailed Analysis
**Chart (a): Qwen-2.5-7B on RGBzh**
* **Answer Accuracy:**
* **No context:** "unknown" ~0.0, "weaklyknown" ~0.0, "maybeknown" ~0.45, "highlyknown" ~0.95
* **0 pos:** "unknown" ~0.05, "weaklyknown" ~0.1, "maybeknown" ~0.12, "highlyknown" ~0.25
* **1 pos:** "unknown" ~0.7, "weaklyknown" ~0.85, "maybeknown" ~0.9, "highlyknown" ~0.95
* **5 pos:** "unknown" ~0.8, "weaklyknown" ~0.9, "maybeknown" ~0.95, "highlyknown" ~0.98
* **Trend:** Accuracy generally increases with more positive context for all knowledge levels.
* **Refusal Rate:**
* **No context:** "unknown" ~0.06, "weaklyknown" ~0.0, "maybeknown" ~0.0, "highlyknown" ~0.0
* **0 pos:** "unknown" ~0.32, "weaklyknown" ~0.30, "maybeknown" ~0.28, "highlyknown" ~0.24
* **1 pos:** "unknown" ~0.01, "weaklyknown" ~0.01, "maybeknown" ~0.0, "highlyknown" ~0.0
* **5 pos:** "unknown" ~0.0, "weaklyknown" ~0.0, "maybeknown" ~0.0, "highlyknown" ~0.0
* **Trend:** Refusal rate is highest with "0 pos" context and decreases significantly with "1 pos" and "5 pos".
**Chart (b): LLaMA-3.1-8B on RGBen**
* **Answer Accuracy:**
* **No context:** "unknown" ~0.0, "weaklyknown" ~0.0, "maybeknown" ~0.5, "highlyknown" ~0.98
* **0 pos:** "unknown" ~0.2, "weaklyknown" ~0.1, "maybeknown" ~0.25, "highlyknown" ~0.55
* **1 pos:** "unknown" ~0.98, "weaklyknown" ~0.98, "maybeknown" ~0.98, "highlyknown" ~0.98
* **5 pos:** "unknown" ~0.98, "weaklyknown" ~0.98, "maybeknown" ~0.98, "highlyknown" ~0.98
* **Trend:** Accuracy increases significantly from "no context" and "0 pos" to "1 pos" and "5 pos", reaching near-perfect accuracy.
* **Refusal Rate:**
* **No context:** "unknown" ~0.07, "weaklyknown" ~0.04, "maybeknown" ~0.0, "highlyknown" ~0.0
* **0 pos:** "unknown" ~0.14, "weaklyknown" ~0.20, "maybeknown" ~0.11, "highlyknown" ~0.04
* **1 pos:** "unknown" ~0.02, "weaklyknown" ~0.02, "maybeknown" ~0.01, "highlyknown" ~0.01
* **5 pos:** "unknown" ~0.02, "weaklyknown" ~0.01, "maybeknown" ~0.01, "highlyknown" ~0.01
* **Trend:** Refusal rate is highest with "0 pos" context and decreases significantly with "1 pos" and "5 pos".
### Key Observations
* Both models show a general trend of increasing answer accuracy and decreasing refusal rate as more positive context is provided.
* The "highlyknown" category consistently exhibits the highest accuracy and lowest refusal rate across all context settings for both models.
* The "0 pos" context setting often results in the highest refusal rates, suggesting that some positive context is needed for optimal performance.
* LLaMA-3.1-8B on RGBen achieves near-perfect accuracy with "1 pos" and "5 pos" contexts, indicating strong performance on this dataset.
### Interpretation
The data suggests that providing more positive context chunks generally improves the performance of both Qwen-2.5-7B and LLaMA-3.1-8B models, leading to higher answer accuracy and lower refusal rates. The "highlyknown" category consistently performs well, indicating that the models are more confident and accurate when dealing with well-known information. The higher refusal rates observed with "0 pos" context highlight the importance of providing some level of positive context for the models to function effectively. LLaMA-3.1-8B's near-perfect accuracy with more context on RGBen suggests it is particularly well-suited for this dataset. The arrows in the image highlight the increase in accuracy from "no context" to "1 pos" for the "highlyknown" category in both models.