TECHNICAL ASSET FINGERPRINT
c7ca53da6101ac6e30a0686c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
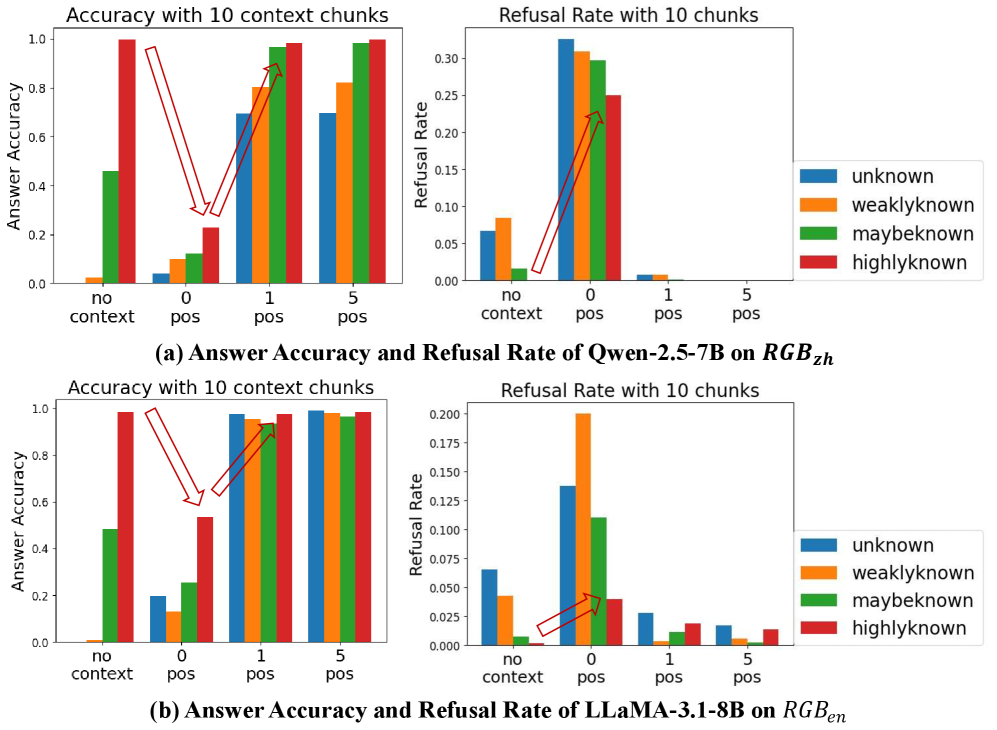
## Bar Charts: Answer Accuracy and Refusal Rate of Two LLMs on Different Knowledge Levels
### Overview
The image displays a composite figure containing four bar charts arranged in a 2x2 grid. The charts are grouped into two horizontal sections, labeled (a) and (b), each analyzing a different Large Language Model (LLM). Section (a) analyzes "Qwen-2.5-7B" on a dataset or task denoted as "$RGB_{zh}$". Section (b) analyzes "LLaMA-3.1-8B" on "$RGB_{en}$". Each section contains two charts: one for "Answer Accuracy" and one for "Refusal Rate". The charts compare performance across four knowledge levels ("unknown", "weaklyknown", "maybeknown", "highlyknown") under four different context conditions ("no context", "0 pos", "1 pos", "5 pos").
### Components/Axes
**Common Elements Across All Charts:**
* **X-Axis (Categories):** Four discrete conditions: "no context", "0 pos", "1 pos", "5 pos". These likely represent the amount or type of contextual information provided to the model.
* **Legend (Right Side of Each Chart):** Four colored bars representing knowledge levels:
* Blue: `unknown`
* Orange: `weaklyknown`
* Green: `maybeknown`
* Red: `highlyknown`
* **Chart Titles:** Each chart has a title at the top: "Accuracy with 10 context chunks" or "Refusal Rate with 10 chunks".
* **Annotations:** Red arrows are drawn on the charts to highlight specific trends between data points.
**Section (a) - Top Row: Qwen-2.5-7B on $RGB_{zh}$**
* **Left Chart - Answer Accuracy:**
* **Y-Axis:** "Answer Accuracy", scale from 0.0 to 1.0.
* **Right Chart - Refusal Rate:**
* **Y-Axis:** "Refusal Rate", scale from 0.00 to 0.30.
* **Caption (Below charts):** "(a) Answer Accuracy and Refusal Rate of Qwen-2.5-7B on $RGB_{zh}$"
**Section (b) - Bottom Row: LLaMA-3.1-8B on $RGB_{en}$**
* **Left Chart - Answer Accuracy:**
* **Y-Axis:** "Answer Accuracy", scale from 0.0 to 1.0.
* **Right Chart - Refusal Rate:**
* **Y-Axis:** "Refusal Rate", scale from 0.000 to 0.200.
* **Caption (Below charts):** "(b) Answer Accuracy and Refusal Rate of LLaMA-3.1-8B on $RGB_{en}$"
### Detailed Analysis
**Trend Verification & Data Point Extraction (Approximate Values):**
**Section (a) - Qwen-2.5-7B:**
* **Answer Accuracy (Left Chart):**
* **Trend:** Accuracy generally increases for all knowledge levels as the context condition moves from "no context" to "5 pos". The increase is most dramatic for `highlyknown` (red).
* **Data Points (Approx.):**
* `no context`: unknown ~0.0, weaklyknown ~0.02, maybeknown ~0.45, highlyknown ~1.0.
* `0 pos`: unknown ~0.04, weaklyknown ~0.10, maybeknown ~0.12, highlyknown ~0.22.
* `1 pos`: unknown ~0.70, weaklyknown ~0.80, maybeknown ~0.95, highlyknown ~0.98.
* `5 pos`: unknown ~0.70, weaklyknown ~0.82, maybeknown ~0.98, highlyknown ~1.0.
* **Refusal Rate (Right Chart):**
* **Trend:** Refusal rate peaks sharply at the "0 pos" condition for `unknown` and `weaklyknown`, then drops to near zero for "1 pos" and "5 pos". `maybeknown` and `highlyknown` show lower refusal rates overall.
* **Data Points (Approx.):**
* `no context`: unknown ~0.07, weaklyknown ~0.08, maybeknown ~0.02, highlyknown ~0.00.
* `0 pos`: unknown ~0.32, weaklyknown ~0.31, maybeknown ~0.30, highlyknown ~0.25.
* `1 pos`: unknown ~0.01, weaklyknown ~0.01, maybeknown ~0.00, highlyknown ~0.00.
* `5 pos`: All values are ~0.00.
**Section (b) - LLaMA-3.1-8B:**
* **Answer Accuracy (Left Chart):**
* **Trend:** Similar upward trend as context improves. `highlyknown` starts high and remains high. Other categories show significant improvement from "no context"/"0 pos" to "1 pos"/"5 pos".
* **Data Points (Approx.):**
* `no context`: unknown ~0.0, weaklyknown ~0.01, maybeknown ~0.48, highlyknown ~0.99.
* `0 pos`: unknown ~0.20, weaklyknown ~0.14, maybeknown ~0.26, highlyknown ~0.54.
* `1 pos`: unknown ~0.98, weaklyknown ~0.95, maybeknown ~0.94, highlyknown ~0.96.
* `5 pos`: unknown ~0.99, weaklyknown ~0.99, maybeknown ~0.97, highlyknown ~0.99.
* **Refusal Rate (Right Chart):**
* **Trend:** Refusal rate peaks at "0 pos", most prominently for `weaklyknown`. Rates are generally lower than for Qwen-2.5-7B and drop significantly with positive context.
* **Data Points (Approx.):**
* `no context`: unknown ~0.065, weaklyknown ~0.045, maybeknown ~0.010, highlyknown ~0.000.
* `0 pos`: unknown ~0.140, weaklyknown ~0.200, maybeknown ~0.110, highlyknown ~0.040.
* `1 pos`: unknown ~0.030, weaklyknown ~0.005, maybeknown ~0.012, highlyknown ~0.020.
* `5 pos`: unknown ~0.020, weaklyknown ~0.005, maybeknown ~0.005, highlyknown ~0.015.
### Key Observations
1. **Context is Critical:** For both models, providing positive context ("1 pos", "5 pos") dramatically increases answer accuracy and reduces refusal rates compared to "no context" or "0 pos" conditions.
2. **The "0 pos" Problem:** The "0 pos" condition (likely meaning zero positive examples in context) causes a severe performance drop, especially for less-known items (`unknown`, `weaklyknown`), where accuracy plummets and refusal rates spike.
3. **Knowledge Level Hierarchy:** There is a clear performance hierarchy: `highlyknown` > `maybeknown` > `weaklyknown` > `unknown`. This holds across most conditions, with the gap narrowing significantly when ample positive context ("1 pos", "5 pos") is provided.
4. **Model Comparison:** LLaMA-3.1-8B (on $RGB_{en}$) appears to achieve higher accuracy with "1 pos" context for the `unknown` category compared to Qwen-2.5-7B (on $RGB_{zh}$). Its refusal rates are also generally lower.
### Interpretation
The data demonstrates a strong interaction between a model's pre-existing knowledge about a topic and the quality of the contextual information provided. The key finding is that **context is not universally beneficial**. The "0 pos" condition acts as a detrimental interference, likely confusing the model or triggering conservative refusal behaviors, particularly for information it is uncertain about (`unknown`, `weaklyknown`).
The charts suggest that for these models to perform well, they need either:
a) Strong pre-existing knowledge (`highlyknown`), or
b) High-quality, positive contextual examples ("1 pos" or "5 pos").
The absence of positive examples ("0 pos") is worse than having no context at all for lower-knowledge items. This has practical implications for prompt engineering and retrieval-augmented generation (RAG) systems: ensuring retrieved context contains relevant, positive examples is crucial, as presenting irrelevant or zero-shot examples can actively harm performance. The difference between the two models' results on $RGB_{zh}$ and $RGB_{en}$ may also point to variations in training data, model architecture, or the inherent difficulty of the tasks in different languages.
DECODING INTELLIGENCE...