\n
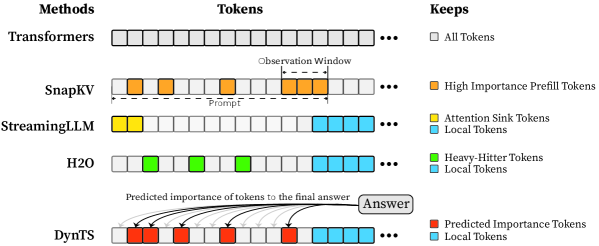
## Diagram: Comparison of Token Handling in Different Methods
### Overview
The image is a diagram comparing how different methods (Transformers, SnapKV, StreamingLLM, H2O, and DynTS) handle tokens during processing. Each method is represented by a horizontal row of boxes representing tokens, with different colors indicating different types of tokens or their importance. Arrows in the DynTS row indicate predicted importance of tokens to the final answer.
### Components/Axes
The diagram is organized into three columns:
* **Methods:** Lists the different methods being compared: Transformers, SnapKV, StreamingLLM, H2O, and DynTS.
* **Tokens:** A visual representation of tokens for each method, using colored boxes. Each row represents a method.
* **Keeps:** A legend explaining the color coding of the tokens in each method.
### Detailed Analysis or Content Details
**1. Transformers:**
* All tokens are represented by gray boxes.
* The "Keeps" label indicates "All Tokens" are kept.
* The tokens extend to the right with an ellipsis (...), indicating a potentially large number of tokens.
**2. SnapKV:**
* The first few tokens are orange, representing "High Importance Prefill Tokens".
* The subsequent tokens are gray.
* A label "Prompt" spans the orange tokens.
* A label "Observation Window" spans a section of the gray tokens.
* The tokens extend to the right with an ellipsis (...).
**3. StreamingLLM:**
* The first token is yellow, representing "Attention Sink Tokens".
* The subsequent tokens are light blue, representing "Local Tokens".
* The tokens extend to the right with an ellipsis (...).
**4. H2O:**
* The first few tokens are green, representing "Heavy-Hitter Tokens".
* The subsequent tokens are light blue, representing "Local Tokens".
* The tokens extend to the right with an ellipsis (...).
**5. DynTS:**
* The first few tokens are red, representing "Predicted Importance Tokens".
* The subsequent tokens are light blue, representing "Local Tokens".
* Curved arrows originate from the red tokens and point towards a box labeled "Answer", indicating the predicted importance of these tokens to the final answer.
* The tokens extend to the right with an ellipsis (...).
### Key Observations
* Transformers process all tokens equally.
* SnapKV prioritizes "High Importance Prefill Tokens" during the prompt phase.
* StreamingLLM uses "Attention Sink Tokens" followed by "Local Tokens".
* H2O identifies and prioritizes "Heavy-Hitter Tokens" followed by "Local Tokens".
* DynTS dynamically predicts the importance of tokens and focuses on those deemed most relevant to the answer.
* The use of ellipsis (...) suggests that the token sequences can be much longer than depicted.
### Interpretation
The diagram illustrates different strategies for managing tokens in language models. Traditional Transformers process all tokens uniformly, which can be computationally expensive. The other methods (SnapKV, StreamingLLM, H2O, and DynTS) attempt to improve efficiency by selectively focusing on the most important tokens.
SnapKV focuses on the initial prompt tokens. StreamingLLM uses attention sink tokens to manage context. H2O identifies key tokens within the sequence. DynTS dynamically assesses token importance and prioritizes those contributing most to the final answer.
The arrows in DynTS visually emphasize the concept of attention and how the model weighs different tokens when generating a response. The diagram suggests a trend towards more sophisticated token management techniques to improve the performance and scalability of language models. The diagram does not provide quantitative data, but rather a qualitative comparison of different approaches.