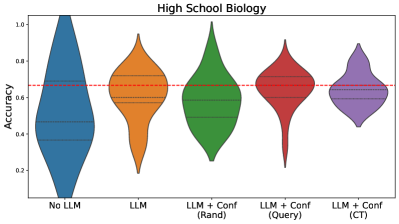
## Violin Plot: High School Biology Accuracy
### Overview
The image is a violin plot comparing the accuracy of different models on a high school biology task. The models include a baseline with no LLM, an LLM alone, and LLMs with confidence measures (random, query-based, and CT-based). The y-axis represents accuracy, and the x-axis represents the different models. A red dashed line indicates a reference accuracy level.
### Components/Axes
* **Title:** High School Biology
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Categorical, representing different models:
* No LLM (Blue)
* LLM (Orange)
* LLM + Conf (Rand) (Green)
* LLM + Conf (Query) (Red)
* LLM + Conf (CT) (Purple)
* **Horizontal Dashed Red Line:** Appears to be a reference line at approximately 0.67 accuracy.
* **Violin Plot Components:** Each violin plot shows the distribution of accuracy for each model. The black dashed lines within each violin plot represent quartiles.
### Detailed Analysis
* **No LLM (Blue):** The "No LLM" model has a wide distribution, with the majority of the data concentrated between 0.3 and 0.6 accuracy.
* **LLM (Orange):** The "LLM" model has a distribution centered around 0.6 accuracy, with a narrower spread than the "No LLM" model.
* **LLM + Conf (Rand) (Green):** The "LLM + Conf (Rand)" model has a distribution similar to the "LLM" model, but slightly shifted upwards, with the majority of the data concentrated between 0.5 and 0.8 accuracy.
* **LLM + Conf (Query) (Red):** The "LLM + Conf (Query)" model has a distribution centered around 0.7 accuracy, with a noticeable tail extending down to lower accuracy values.
* **LLM + Conf (CT) (Purple):** The "LLM + Conf (CT)" model has a distribution centered around 0.65 accuracy, with a narrower spread than the other LLM-based models.
### Key Observations
* The addition of an LLM generally improves accuracy compared to the "No LLM" baseline.
* Confidence measures, particularly the query-based approach, appear to further enhance accuracy.
* The "LLM + Conf (Query)" model has the highest median accuracy but also exhibits a wider range of performance.
* The red dashed line at approximately 0.67 accuracy seems to be a target or threshold.
### Interpretation
The violin plot suggests that using an LLM improves the accuracy of the high school biology task. Furthermore, incorporating confidence measures, especially using a query-based approach, can lead to even better performance. However, the wider distribution of the "LLM + Conf (Query)" model indicates that its performance may be more variable. The "No LLM" model has the lowest accuracy, indicating the value of using an LLM for this task. The red line may represent a minimum acceptable accuracy, and the models that consistently perform above this line are likely preferred.