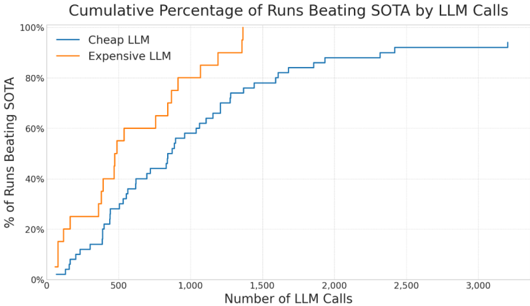
## Line Chart: Cumulative Percentage of Runs Beating SOTA by LLM Calls
### Overview
The chart compares the performance of two language models (Cheap LLM and Expensive LLM) in terms of the percentage of runs that beat a state-of-the-art (SOTA) benchmark as a function of the number of LLM calls made. The data is presented as cumulative percentages, with two distinct lines representing each model's performance trajectory.
### Components/Axes
- **X-axis**: "Number of LLM Calls" (0 to 3,000, in increments of 500).
- **Y-axis**: "% of Runs Beating SOTA" (0% to 100%, in increments of 20%).
- **Legend**: Located in the top-right corner, with:
- **Blue line**: "Cheap LLM"
- **Orange line**: "Expensive LLM"
### Detailed Analysis
1. **Cheap LLM (Blue Line)**:
- Starts at ~0% at 0 calls.
- Gradually increases, reaching ~20% at 500 calls.
- Accelerates growth, hitting ~60% at 1,000 calls.
- Crosses the Expensive LLM line near 1,500 calls (~70%).
- Reaches ~85% at 2,000 calls.
- Plateaus at ~95% by 2,500 calls, stabilizing at 100% by 3,000 calls.
2. **Expensive LLM (Orange Line)**:
- Starts at ~0% at 0 calls.
- Rises sharply, reaching ~40% at 500 calls.
- Accelerates further, hitting ~80% at 1,000 calls.
- Peaks at 100% near 1,500 calls.
- Remains at 100% for all subsequent call counts (1,500–3,000).
### Key Observations
- The **Expensive LLM** achieves 100% performance significantly earlier (~1,500 calls) compared to the **Cheap LLM** (~3,000 calls).
- The **Cheap LLM** overtakes the Expensive LLM in performance around 1,500 calls, suggesting diminishing returns for the Expensive LLM beyond this point.
- Both models plateau at 100% performance, but the Cheap LLM requires more calls to reach this threshold.
### Interpretation
The data suggests that while the Expensive LLM delivers faster initial gains, the Cheap LLM becomes more effective at higher call volumes, potentially due to optimization, learning, or cost-efficiency tradeoffs. The crossover point (~1,500 calls) highlights a critical threshold where cost considerations may outweigh performance benefits for the Expensive LLM. This could inform decisions about resource allocation in LLM deployment, favoring cheaper models for large-scale applications where marginal gains from expensive models are negligible.