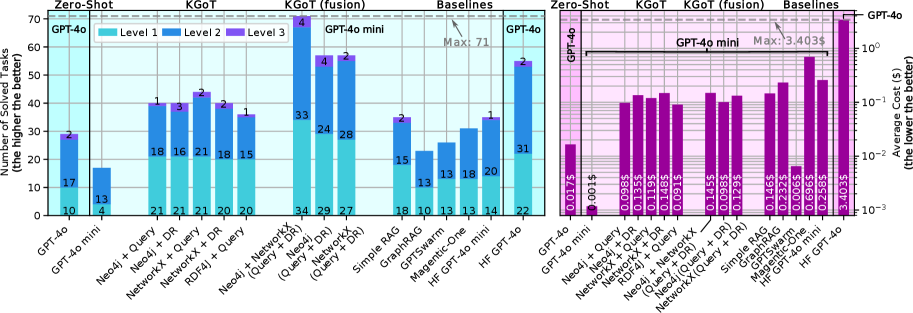
## Bar Charts: Performance and Cost Comparison of Different Models
### Overview
The image presents two bar charts comparing the performance and average cost of different models, including GPT-4o, GPT-4o mini, and various knowledge graph-enhanced models (KGOT and KGOT fusion) and baselines. The left chart displays the number of solved tasks (higher is better), while the right chart shows the average cost in dollars (lower is better) on a logarithmic scale.
### Components/Axes
**Left Chart (Number of Solved Tasks):**
* **Title:** Number of Solved Tasks (the higher the better)
* **Y-axis:** Number of Solved Tasks, ranging from 0 to 70.
* **X-axis:** Different models and configurations: GPT-4o, GPT-4o mini, Neo4j + Query, NetworkX + Query, Neo4j + DR, NetworkX + DR, RDF4J + Query, Neo4j + NetworkX (Query + DR), Simple RAG, GraphRAG, GPTSwarm, Magentic-One, HF GPT-4o mini, HF GPT-4o.
* **Bar Colors (Legend, located at the top-center of the chart):**
* Level 1: Light Blue
* Level 2: Blue
* Level 3: Purple
* **Sections:** Zero-Shot, KGOT, KGOT (fusion), Baselines.
* **Maximum Solved Tasks:** Indicated by an arrow pointing to the top of the GPT-4o bar in the Baselines section, labeled "Max: 71".
**Right Chart (Average Cost):**
* **Title:** Average Cost ($) (the lower the better)
* **Y-axis:** Average Cost ($) on a logarithmic scale, ranging from 10^-3 to 10^0 (0.001 to 1).
* **X-axis:** Same models and configurations as the left chart.
* **Bar Color:** Purple
* **Sections:** Zero-Shot, KGOT, KGOT (fusion), Baselines.
* **Maximum Cost:** Indicated by an arrow pointing to the top of the GPT-4o bar in the Baselines section, labeled "Max: 3.403$".
### Detailed Analysis
**Left Chart (Number of Solved Tasks):**
* **GPT-4o:**
* Zero-Shot: Level 1: 10, Level 2: 17, Level 3: 2, Total: 29
* Baselines: Level 1: 22, Level 2: 31, Total: 53
* **GPT-4o mini:**
* Zero-Shot: Level 1: 4, Level 2: 13, Total: 17
* KGOT (fusion): Level 1: 20, Level 2: 18, Level 3: 1, Total: 39
* **Neo4j + Query:**
* KGOT: Level 1: 21, Level 2: 18, Level 3: 1, Total: 40
* **NetworkX + Query:**
* KGOT: Level 1: 21, Level 2: 16, Level 3: 3, Total: 40
* **Neo4j + DR:**
* KGOT: Level 1: 21, Level 2: 21, Total: 42
* KGOT (fusion): Level 1: 34, Level 2: 33, Level 3: 4, Total: 71
* **NetworkX + DR:**
* KGOT: Level 1: 20, Level 2: 18, Level 3: 2, Total: 40
* KGOT (fusion): Level 1: 29, Level 2: 24, Level 3: 4, Total: 57
* **RDF4J + Query:**
* KGOT: Level 1: 20, Level 2: 15, Level 3: 1, Total: 36
* **Neo4j + NetworkX (Query + DR):**
* KGOT (fusion): Level 1: 27, Level 2: 28, Level 3: 2, Total: 57
* **Simple RAG:**
* Baselines: Level 1: 18, Level 2: 15, Level 3: 2, Total: 35
* **GraphRAG:**
* Baselines: Level 1: 10, Level 2: 13, Total: 23
* **GPTSwarm:**
* Baselines: Level 1: 13, Level 2: 13, Total: 26
* **Magentic-One:**
* Baselines: Level 1: 13, Level 2: 18, Level 3: 1, Total: 32
* **HF GPT-4o mini:**
* Baselines: Level 1: 14, Level 2: 20, Total: 34
**Right Chart (Average Cost):**
* **GPT-4o:**
* Zero-Shot: 0.017$
* Baselines: 3.403$
* **GPT-4o mini:**
* Zero-Shot: 0.001$
* KGOT (fusion): 0.696$
* **Neo4j + Query:**
* KGOT: 0.098$
* **NetworkX + Query:**
* KGOT: 0.135$
* **Neo4j + DR:**
* KGOT: 0.119$
* KGOT (fusion): 0.145$
* **NetworkX + DR:**
* KGOT: 0.148$
* KGOT (fusion): 0.098$
* **RDF4J + Query:**
* KGOT: 0.091$
* **Neo4j + NetworkX (Query + DR):**
* KGOT (fusion): 0.146$
* **Simple RAG:**
* Baselines: 0.232$
* **GraphRAG:**
* Baselines: 0.006$
* **GPTSwarm:**
* Baselines: 0.696$
* **Magentic-One:**
* Baselines: 0.258$
* **HF GPT-4o mini:**
* Baselines: 0.258$
### Key Observations
* **Performance:** The Neo4j + DR model under KGOT (fusion) achieves the highest number of solved tasks (71), matching the maximum possible. GPT-4o also performs well, especially in the Baselines section.
* **Cost:** GPT-4o mini in the Zero-Shot setting has the lowest average cost (0.001$). GPT-4o in the Baselines section has the highest cost (3.403$).
* **Trade-off:** There is a clear trade-off between performance and cost. Models with higher performance tend to have higher costs.
* **KGOT Fusion:** KGOT fusion models generally outperform their KGOT counterparts in terms of the number of solved tasks.
### Interpretation
The data suggests that KGOT fusion, particularly with Neo4j + DR, significantly enhances the performance of the models in terms of the number of solved tasks. However, this performance comes at a cost, as these models are not the cheapest. GPT-4o mini offers a low-cost solution, but its performance is lower than the KGOT fusion models.
The choice of model depends on the specific requirements and constraints of the application. If performance is the primary concern, KGOT fusion with Neo4j + DR is a good option. If cost is a major factor, GPT-4o mini in the Zero-Shot setting might be more suitable. GPT-4o in the Baselines section is the most expensive and does not offer a proportionally higher number of solved tasks compared to other models, indicating a less efficient trade-off.
The different levels (Level 1, Level 2, Level 3) in the left chart likely represent different difficulty levels or types of tasks. The distribution of these levels across different models provides insights into their strengths and weaknesses in handling various types of tasks.