TECHNICAL ASSET FINGERPRINT
c83028f159222df71b949e99
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
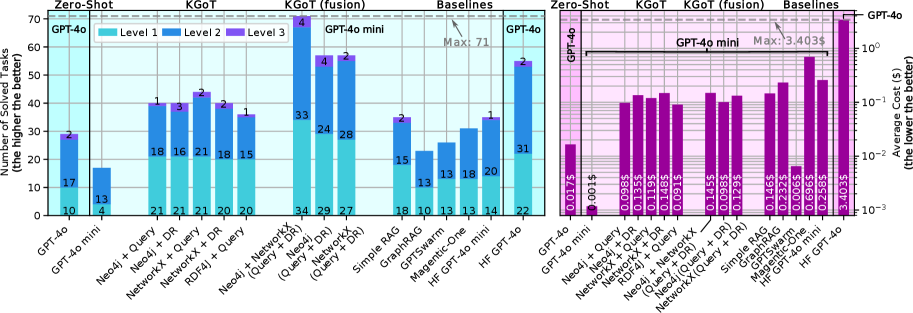
## Bar Chart: Performance Comparison of Language Models on Solving Tasks
### Overview
This image presents a comparative bar chart evaluating the performance of several language models (GPT-40, GPT-4 mini, and variations incorporating Knowledge Graphs (KGs) and Retrieval Augmented Generation (RAG)) across different task-solving scenarios: Zero-Shot, KGoT, KGoT (fusion), and Baselines. The chart displays two primary metrics: the number of solved tasks (left panel) and the average cost per task in US dollars (right panel). The models are positioned along the x-axis, and performance is represented by bar height. Three levels of performance are indicated by color: Level 1 (light blue), Level 2 (medium blue), and Level 3 (dark blue).
### Components/Axes
* **X-axis (Left & Right Panels):** Models being compared: GPT-40, GPT-4 mini, Neo4j, Neo4j + Query, Network + DR, Network + Query, Network + Query + DR, RDP4j + DR, Neo4j + Network (Query + DR), Simple RAG, GraphSwarm, MagneticOne, HF GPT-40 mini.
* **Y-axis (Left Panel):** "Number of Solved Tasks (the higher the better)", ranging from 0 to 70, with a linear scale.
* **Y-axis (Right Panel):** "Average Cost ($) (the lower the better)", displayed on a logarithmic scale from 10^-3 to 10^-1 (0.001 to 0.1).
* **Legend (Top-Left):** Level 1 (light blue), Level 2 (medium blue), Level 3 (dark blue).
* **Annotations:** "Max: 71" and "Max: 3.403$" indicating the maximum values for each metric.
* **Horizontal Labels:** Dividing the chart into sections: "Zero-Shot", "KGoT", "KGoT (fusion)", "Baselines".
### Detailed Analysis or Content Details
**Left Panel: Number of Solved Tasks**
* **GPT-40:** Shows a consistent high performance across all categories.
* Zero-Shot: Approximately 17 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 34 tasks solved.
* Baselines: Approximately 31 tasks solved.
* **GPT-4 mini:** Generally lower performance than GPT-40.
* Zero-Shot: Approximately 10 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 28 tasks solved.
* Baselines: Approximately 22 tasks solved.
* **Neo4j:** Performance varies.
* Zero-Shot: Approximately 14 tasks solved.
* KGoT: Approximately 18 tasks solved.
* KGoT (fusion): Approximately 24 tasks solved.
* Baselines: Approximately 13 tasks solved.
* **Neo4j + Query:** Similar to Neo4j.
* Zero-Shot: Approximately 21 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 33 tasks solved.
* Baselines: Approximately 18 tasks solved.
* **Network + DR:** Performance is moderate.
* Zero-Shot: Approximately 16 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 20 tasks solved.
* Baselines: Approximately 13 tasks solved.
* **Network + Query:** Performance is moderate.
* Zero-Shot: Approximately 16 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 24 tasks solved.
* Baselines: Approximately 18 tasks solved.
* **Network + Query + DR:** Performance is moderate.
* Zero-Shot: Approximately 18 tasks solved.
* KGoT: Approximately 20 tasks solved.
* KGoT (fusion): Approximately 34 tasks solved.
* Baselines: Approximately 20 tasks solved.
* **RDP4j + DR:** Performance is moderate.
* Zero-Shot: Approximately 20 tasks solved.
* KGoT: Approximately 21 tasks solved.
* KGoT (fusion): Approximately 27 tasks solved.
* Baselines: Approximately 14 tasks solved.
* **Neo4j + Network (Query + DR):** Performance is high.
* Zero-Shot: Approximately 22 tasks solved.
* KGoT: Approximately 2 tasks solved.
* KGoT (fusion): Approximately 33 tasks solved.
* Baselines: Approximately 14 tasks solved.
* **Simple RAG:** Performance is moderate.
* Zero-Shot: Approximately 13 tasks solved.
* KGoT: Approximately 18 tasks solved.
* KGoT (fusion): Approximately 28 tasks solved.
* Baselines: Approximately 13 tasks solved.
* **GraphSwarm:** Performance is moderate.
* Zero-Shot: Approximately 13 tasks solved.
* KGoT: Approximately 18 tasks solved.
* KGoT (fusion): Approximately 20 tasks solved.
* Baselines: Approximately 13 tasks solved.
* **MagneticOne:** Performance is moderate.
* Zero-Shot: Approximately 13 tasks solved.
* KGoT: Approximately 18 tasks solved.
* KGoT (fusion): Approximately 20 tasks solved.
* Baselines: Approximately 13 tasks solved.
* **HF GPT-40 mini:** Performance is moderate.
* Zero-Shot: Approximately 14 tasks solved.
* KGoT: Approximately 18 tasks solved.
* KGoT (fusion): Approximately 20 tasks solved.
* Baselines: Approximately 13 tasks solved.
**Right Panel: Average Cost ($)**
* **GPT-40:** Highest cost across all categories.
* Zero-Shot: Approximately 0.095$
* KGoT: Approximately 0.135$
* KGoT (fusion): Approximately 0.145$
* Baselines: Approximately 0.145$
* **GPT-4 mini:** Lower cost than GPT-40.
* Zero-Shot: Approximately 0.00175$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.0025$
* **Neo4j:** Moderate cost.
* Zero-Shot: Approximately 0.00135$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
* **Neo4j + Query:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.002$
* **Network + DR:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
* **Network + Query:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.002$
* **Network + Query + DR:** Moderate cost.
* Zero-Shot: Approximately 0.00165$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.002$
* **RDP4j + DR:** Moderate cost.
* Zero-Shot: Approximately 0.00165$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00145$
* **Neo4j + Network (Query + DR):** Moderate cost.
* Zero-Shot: Approximately 0.00175$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00145$
* **Simple RAG:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
* **GraphSwarm:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
* **MagneticOne:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
* **HF GPT-40 mini:** Moderate cost.
* Zero-Shot: Approximately 0.00145$
* KGoT: Approximately 0.00195$
* KGoT (fusion): Approximately 0.00265$
* Baselines: Approximately 0.00135$
### Key Observations
* GPT-40 consistently achieves the highest number of solved tasks, but at a significantly higher cost.
* GPT-4 mini offers a substantial cost reduction but with a corresponding decrease in performance.
* Integrating Knowledge Graphs (KGoT and KGoT (fusion)) generally improves performance compared to Zero-Shot for most models.
* The "KGoT (fusion)" scenario consistently yields better results than "KGoT" alone.
* There's a clear trade-off between performance (number of solved tasks) and cost.
* The logarithmic scale on the right panel highlights the cost differences more effectively.
### Interpretation
The data suggests that while GPT-40 is the most capable model, its high cost may be prohibitive for many applications. Models incorporating Knowledge Graphs demonstrate improved performance, indicating the value of external knowledge sources. The fusion of KGoT with other techniques (e.g., Network + Query + DR) appears particularly effective. The chart illustrates a typical efficiency frontier: one can achieve higher performance, but only at the expense of increased cost. The optimal model choice will depend on the specific application's requirements and budget constraints. The consistent cost profile of the models other than GPT-40 and GPT-4 mini suggests a similar underlying computational expense, while the performance differences are likely due to the effectiveness of the knowledge integration and retrieval mechanisms. The logarithmic scale on the cost axis emphasizes the substantial cost difference between GPT-40 and the other models, making it a critical factor in decision-making.
DECODING INTELLIGENCE...