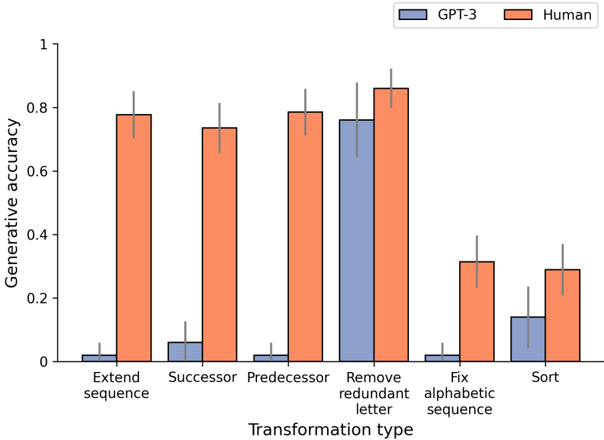
## Grouped Bar Chart: Generative Accuracy by Transformation Type
### Overview
The image is a grouped bar chart comparing the generative accuracy of two entities—GPT-3 (blue bars) and Human (orange bars)—across six different transformation tasks. The chart includes error bars for each data point, indicating variability or confidence intervals.
### Components/Axes
- **Chart Type**: Grouped bar chart (vertical bars).
- **X-axis (Horizontal)**: Labeled "Transformation type". It lists six categorical tasks:
1. Extend sequence
2. Successor
3. Predecessor
4. Remove redundant letter
5. Fix alphabetic sequence
6. Sort
- **Y-axis (Vertical)**: Labeled "Generative accuracy". The scale ranges from 0 to 1, with major tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.
- **Legend**: Located in the top-right corner of the chart area. It defines the two data series:
- **GPT-3**: Represented by blue bars.
- **Human**: Represented by orange bars.
- **Error Bars**: Each bar has a thin, vertical black line extending above and below the top of the bar, representing the margin of error or standard deviation.
### Detailed Analysis
The following table reconstructs the approximate generative accuracy values for each transformation type, based on visual estimation against the y-axis. Uncertainty is noted based on the visible error bars.
| Transformation Type | GPT-3 (Blue) Accuracy | GPT-3 Error (±) | Human (Orange) Accuracy | Human Error (±) |
| :--- | :--- | :--- | :--- | :--- |
| **Extend sequence** | ~0.02 | ~0.05 | ~0.78 | ~0.07 |
| **Successor** | ~0.06 | ~0.08 | ~0.74 | ~0.07 |
| **Predecessor** | ~0.02 | ~0.05 | ~0.79 | ~0.07 |
| **Remove redundant letter** | ~0.76 | ~0.12 | ~0.86 | ~0.07 |
| **Fix alphabetic sequence** | ~0.02 | ~0.05 | ~0.32 | ~0.08 |
| **Sort** | ~0.14 | ~0.10 | ~0.29 | ~0.08 |
**Trend Verification per Series:**
- **GPT-3 (Blue Bars)**: The trend is predominantly very low accuracy (near 0) for five of the six tasks. There is one significant outlier: the "Remove redundant letter" task, where accuracy spikes to approximately 0.76. The "Sort" task shows a minor increase to ~0.14.
- **Human (Orange Bars)**: The trend shows consistently higher accuracy than GPT-3 across all tasks. Performance is highest (above 0.7) for the first four tasks ("Extend sequence", "Successor", "Predecessor", "Remove redundant letter"). There is a notable drop in accuracy for the last two tasks ("Fix alphabetic sequence" and "Sort"), falling to the 0.29-0.32 range.
### Key Observations
1. **Performance Gap**: Humans significantly outperform GPT-3 on five out of the six transformation tasks. The gap is most extreme for "Extend sequence," "Successor," and "Predecessor," where human accuracy is over 0.7 and GPT-3 accuracy is near 0.
2. **GPT-3's Exception**: The "Remove redundant letter" task is the only one where GPT-3 achieves high accuracy (~0.76), coming close to human performance (~0.86). This suggests this specific task may align well with GPT-3's capabilities.
3. **Task Difficulty**: The tasks "Fix alphabetic sequence" and "Sort" appear to be the most challenging for both entities, as they yield the lowest scores for humans and only marginally better scores for GPT-3 compared to its baseline.
4. **Error Bars**: The error bars for GPT-3 are generally larger relative to its bar height (especially for "Sort"), indicating higher variability or less certainty in its performance on those tasks. Human error bars are more consistent in size.
### Interpretation
This chart demonstrates a clear disparity in generative accuracy between a large language model (GPT-3) and humans across a set of symbolic or logical transformation tasks. The data suggests that while humans possess a robust and generalizable ability to perform these sequence-based transformations, GPT-3's capability is highly task-specific.
The model fails almost completely at tasks requiring understanding of sequence extension, succession, and precedence, which may involve deeper semantic or logical reasoning about order and relationships. Its near-perfect performance on "Remove redundant letter" indicates strength in a more localized, pattern-matching task that likely doesn't require maintaining or manipulating a broader sequence context.
The drop in human performance on "Fix alphabetic sequence" and "Sort" is interesting. It may indicate these tasks are more cognitively demanding or prone to error for humans, or that the specific test cases were more difficult. The fact that GPT-3 shows only slight improvement here suggests these tasks remain challenging for the model as well.
Overall, the visualization highlights the limitations of the evaluated language model in replicating human-like performance on a range of fundamental generative and logical tasks, pinpointing specific areas of relative strength and profound weakness.